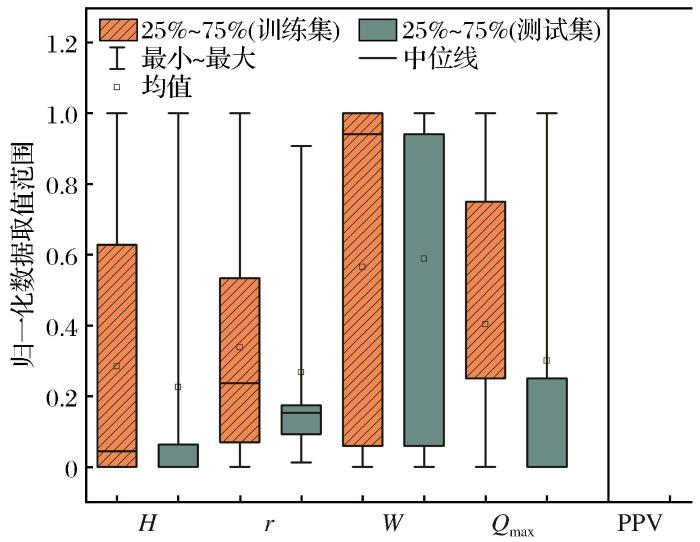
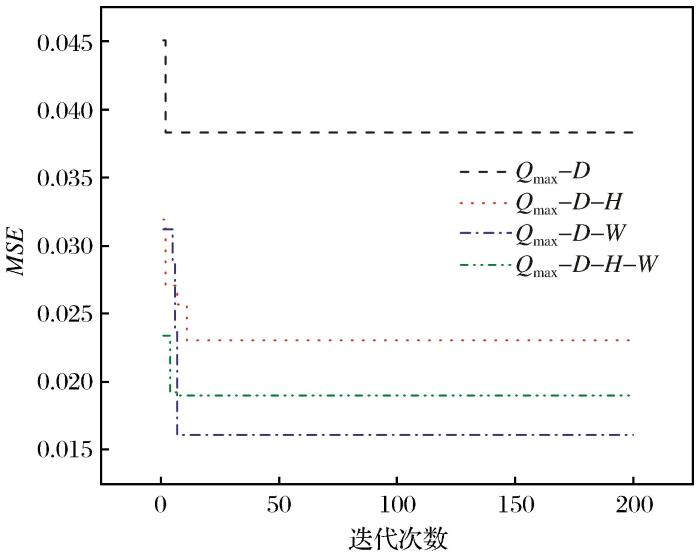
The vibration caused by blasting is likely to cause instability and failure of facilities such as underground roadways,high and steep slopes in mining areas or ground buildings under dynamic action.Therefore,it is particularly important to predict the intensity of blasting vibration.The accurate prediction of peak particle velocity(PPV) is the premise of effectively controlling the vibration hazard of blasting engineering,but the current empirical formula for predicting the peak particle velocity is not accurate enough.Machine learning has obvious advantages in solving the problem of nonlinear relationship.In order to improve the prediction accuracy of the PPV prediction model,this study proposes to optimize the number of trees and the minimum number of leaf points in the random forest (RF)by slime mould algorithm (SMA) ,which overcomes the inability to obtain the optimal hyperparameters by using a single RF algorithm.Based on a dataset of 23 samples with four input parameters (minimum resistance line-r,height difference-H,maximum segment dose-Qmax,horizontal distance-W) and one output parameter(PPV) collected in an open-pit blasting engineering example,the combination of four parameters of these four parameters (Qmax-H-W-r、Qmax-H-r、Qmax-W-r、Qmax-r) was used as the input parameters in the RF algorithm,and then MAE,RMSE,MEDEA and R2 evaluate the prediction effect of the SMA-RF model for four different input parameters to determine the optimal combination of parameters.In this model,the fitness function in SMA is defined as the root mean square error of the predicted value to enhance the robustness of the RF model.Then,the performance of SMA-RF model and unoptimized RF model and six empirical formulas commonly used in China and abroad were compared.The results show that the SMA-RF model has better prediction accuracy than the RF model,and the SMA-RF model has significantly better prediction effect than the six empirical formulas.In addition,Qmax-H-W-r can train the optimal SMA-RF model in the combination of four parameters,so it is recommended to be used to predict PPV in engineering practice.
DENG Hongwei, LUO Liang. PPV Prediction Model Based on Random Forest Optimized by SMA Algorithm[J]. Gold Science and Technology, 2023, 31(4): 624-634 doi:10.11872/j.issn.1005-2518.2023.04.026
爆破是露天开采过程中的重要技术手段,除了要确保开挖岩土充分破碎外,还要保证爆破振动水平控制在一定范围内,以减少爆破对周围建筑和人员的危害(李萧翰等,2019)。爆破振动质点速度峰值(Peak Particle Velocity,PPV)是衡量爆破振动对结构影响的重要指标。然而爆破振动质点速度受到爆破参数(如孔深、孔径、段药量、段间隔、爆破点和爆破持续时间等)、岩体性质参数(如岩体的纵波波速等)和地形地貌等众多因素的影响(Hu et al.,2018;范勇等,2022),而且这些因素之间存在复杂的非线性关系。
近年来,越来越多的学者运用机器学习方法来探究爆破振动速度与其影响因素之间的非线性关系。BP神经网络适用于PPV预测,但基于BP神经网络建立起来的模型存在一定的缺陷,其自身存在过拟合以及初始权值和阈值的取值问题会使得预测结果出现不稳定等缺点(范勇等,2022);RVM的缺点是训练过程涉及到优化一个非凸的函数,且精度较SVM偏低(张研等,2022)。而随机森林对多元共线性不敏感,预测结果对缺失数据和非平衡数据比较稳健(陈绎冰等,2022),且随机森林对训练样本要求不高。SMA算法具备良好的全局寻优能力(Lin et al.,2022),通过SMA算法准确优化随机森林的超参数可进一步提高预测的准确性。鉴于此,提出构建基于SMA算法优化随机森林的PPV预测模型。
1 方法原理
1.1 随机森林算法
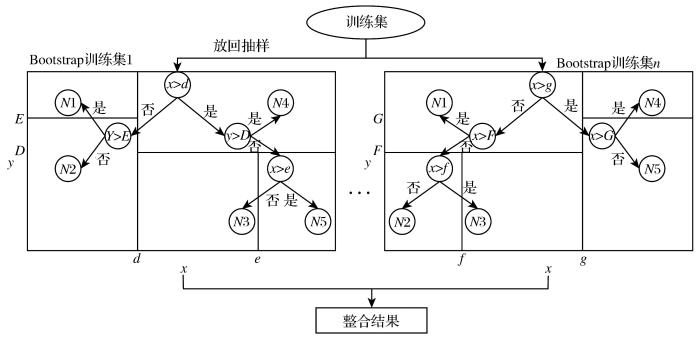
随机森林是一种结合Bagging装袋法生成多个相互独立的分类和回归树(Classification and Regres-sion Tree,CART)进行分类和预测的集成算法(Brei-man,2001)。主要原理是依靠结合多个决策树,并平均其结果使得决策树泛化误差收敛从而产生更好的预测结果(Lee et al.,2010)。随机森林模型的原理是在CART决策树中使用Bagging算法在样本集进行有放回的抽样,抽取多个大小与原样本集相同的训练样本集,完成对集成模型的构建(图1)。随机森林算法的思想是对遭受高方差的多棵决策树进行平均,从而构建一个具有更好泛化性能且更不容易出现过拟合且更稳健的模型。随机森林构建的基本步骤(Lee et al.,2010;刘强等,2018)如下:
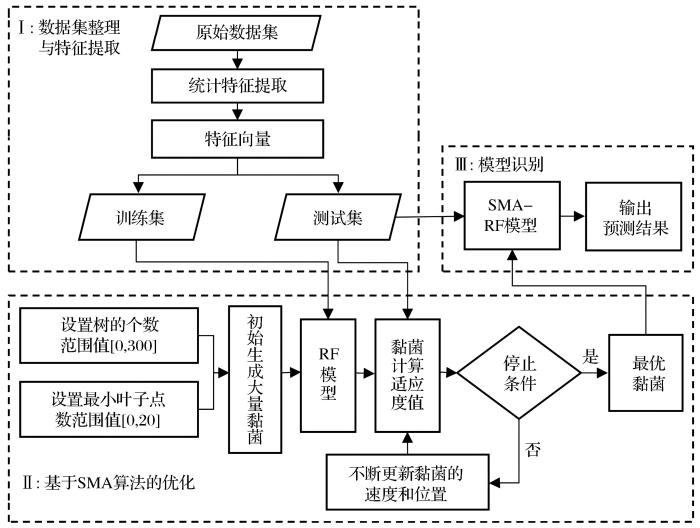
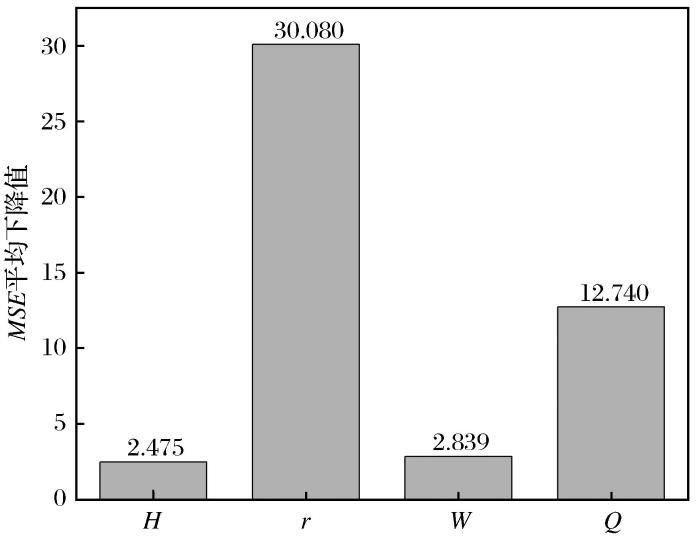
RF模型的预测精度和速度受树的个数和最小叶子点数等超参数的影响较大。当树的个数过少时模型容易欠拟合,而树的个数过多时既不能显著提升模型,又会增加模型的计算时间;同样随着最小叶子点数的增加,拟合效果会不断优化,同时模型的计算复杂度也会随之增加(杨练兵等,2021)。因此,设置合适的树的个数和最小叶子点数显得尤为重要。SMA具有良好的全局优化能力和收敛性(Li et al.,2020),可以优化RF模型的超参数,从而提高其准确性。因此,本文提出了一种SMA-RF算法,该算法利用SMA优化RF的上述2个重要超参数,并将其应用于PPV预测。
为了评价本研究中混合模型的可靠性和准确性,通过模型评价指标决定系数(R2)、平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)和中位数绝对误差(Median Absolute Error,MEDEA)的性能得分对模型性能进行对比评价(Zhang et al.,2020)。这些评价指标用于描述PPV预测值与实测值之间的关系。R2表示实测值与预测值的线性相关性,MAE表示结果的偏差,RMSE表示结果的离散度,MEDEA表示结果的准确度。评价指标的计算公式如下:
Research on the relationship between typhoon precipitation cloud spectrum and precipitation based on random forest and remote sensing
0
2022
Ground vibration from shallow sub-surface blasts
1
1964
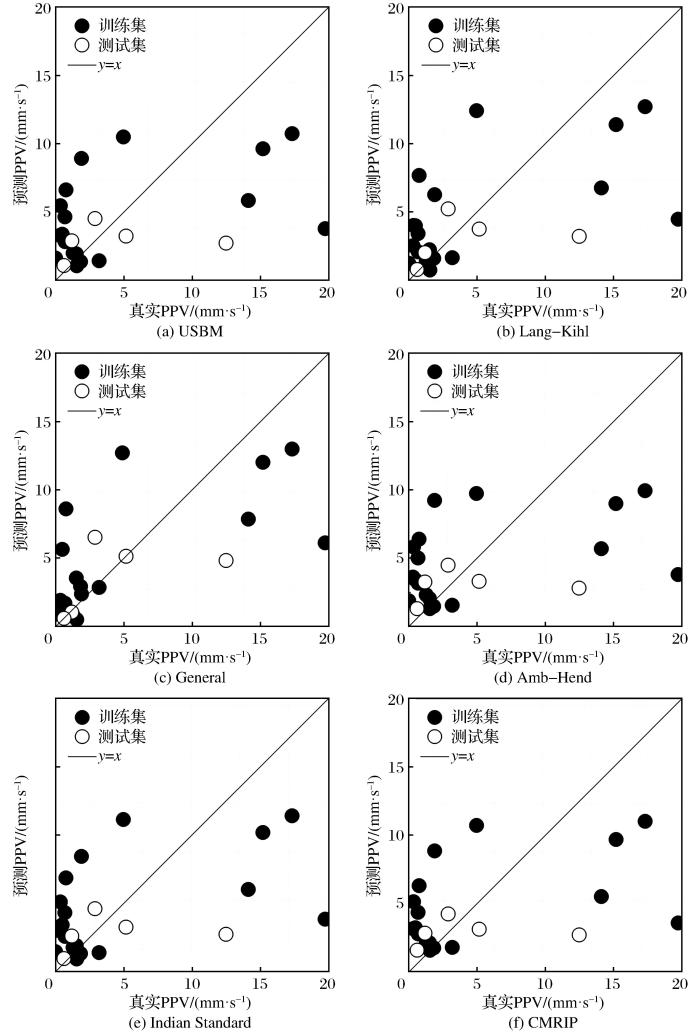
... 在以往研究中,国内外学者相继提出不同的爆破振动速度峰值预测公式,如:Amb-Hend、CMRI predictor(Roy,1993)、General predictor(Davies et al.,1964)、Indian Standard predictor(Guo et al., 2021)、Lang-Kihl和USBM (Siskind et al.,1980),其一般形式为 ...
Prediction of blasting vibration velocity peak based on an improved PSO-BP neural network
0
2022
Predition of blasting vibration velocity using GA-BP neural network
0
2020
Deep neural network and whale optimization algorithm to assess flyrock induced by blasting
1
2021
... 在以往研究中,国内外学者相继提出不同的爆破振动速度峰值预测公式,如:Amb-Hend、CMRI predictor(Roy,1993)、General predictor(Davies et al.,1964)、Indian Standard predictor(Guo et al., 2021)、Lang-Kihl和USBM (Siskind et al.,1980),其一般形式为 ...
A new approach for predicting bench blasting-induced ground vibrations:A case study
1
2018
... 爆破是露天开采过程中的重要技术手段,除了要确保开挖岩土充分破碎外,还要保证爆破振动水平控制在一定范围内,以减少爆破对周围建筑和人员的危害(李萧翰等,2019).爆破振动质点速度峰值(Peak Particle Velocity,PPV)是衡量爆破振动对结构影响的重要指标.然而爆破振动质点速度受到爆破参数(如孔深、孔径、段药量、段间隔、爆破点和爆破持续时间等)、岩体性质参数(如岩体的纵波波速等)和地形地貌等众多因素的影响(Hu et al.,2018;范勇等,2022),而且这些因素之间存在复杂的非线性关系. ...
Altitude effect of blasting vibration velocity in rock slopes
0
2014
Random forest based lung nodule classification aided by clustering
2
2010
... 随机森林是一种结合Bagging装袋法生成多个相互独立的分类和回归树(Classification and Regres-sion Tree,CART)进行分类和预测的集成算法(Brei-man,2001).主要原理是依靠结合多个决策树,并平均其结果使得决策树泛化误差收敛从而产生更好的预测结果(Lee et al.,2010).随机森林模型的原理是在CART决策树中使用Bagging算法在样本集进行有放回的抽样,抽取多个大小与原样本集相同的训练样本集,完成对集成模型的构建(图1).随机森林算法的思想是对遭受高方差的多棵决策树进行平均,从而构建一个具有更好泛化性能且更不容易出现过拟合且更稳健的模型.随机森林构建的基本步骤(Lee et al.,2010;刘强等,2018)如下: ...
... ).随机森林算法的思想是对遭受高方差的多棵决策树进行平均,从而构建一个具有更好泛化性能且更不容易出现过拟合且更稳健的模型.随机森林构建的基本步骤(Lee et al.,2010;刘强等,2018)如下: ...
Slime mould algorithm:A new method for stochastic optimization
2
2020
... SMA算法是2020年提出的一种随机优化的方法,其根据黏菌多头绒泡菌在觅食过程中的行为和形态变化建立数学模型,模拟黏菌获取食物的3种过程:接近食物、包围食物和捕获食物(Li et al.,2020). ...
... RF模型的预测精度和速度受树的个数和最小叶子点数等超参数的影响较大.当树的个数过少时模型容易欠拟合,而树的个数过多时既不能显著提升模型,又会增加模型的计算时间;同样随着最小叶子点数的增加,拟合效果会不断优化,同时模型的计算复杂度也会随之增加(杨练兵等,2021).因此,设置合适的树的个数和最小叶子点数显得尤为重要.SMA具有良好的全局优化能力和收敛性(Li et al.,2020),可以优化RF模型的超参数,从而提高其准确性.因此,本文提出了一种SMA-RF算法,该算法利用SMA优化RF的上述2个重要超参数,并将其应用于PPV预测. ...
Analysis of blasting vibration effects under different ground stress
0
2019
Adaptive slime mould algorithm for optimal design of photovoltaic models
1
2022
... 近年来,越来越多的学者运用机器学习方法来探究爆破振动速度与其影响因素之间的非线性关系.BP神经网络适用于PPV预测,但基于BP神经网络建立起来的模型存在一定的缺陷,其自身存在过拟合以及初始权值和阈值的取值问题会使得预测结果出现不稳定等缺点(范勇等,2022);RVM的缺点是训练过程涉及到优化一个非凸的函数,且精度较SVM偏低(张研等,2022).而随机森林对多元共线性不敏感,预测结果对缺失数据和非平衡数据比较稳健(陈绎冰等,2022),且随机森林对训练样本要求不高.SMA算法具备良好的全局寻优能力(Lin et al.,2022),通过SMA算法准确优化随机森林的超参数可进一步提高预测的准确性.鉴于此,提出构建基于SMA算法优化随机森林的PPV预测模型. ...
PCA-RF model for the classification of rock mass quality and its application
0
2018
Correction of blasting vibration propagation attenuation formula under complex terrain based on dimensional theory
0
2020
Putting ground vibration predictions into practice
1
1993
... 在以往研究中,国内外学者相继提出不同的爆破振动速度峰值预测公式,如:Amb-Hend、CMRI predictor(Roy,1993)、General predictor(Davies et al.,1964)、Indian Standard predictor(Guo et al., 2021)、Lang-Kihl和USBM (Siskind et al.,1980),其一般形式为 ...
Structure response and damage produced by ground vibration from surface mine blasting
1
1980
... 在以往研究中,国内外学者相继提出不同的爆破振动速度峰值预测公式,如:Amb-Hend、CMRI predictor(Roy,1993)、General predictor(Davies et al.,1964)、Indian Standard predictor(Guo et al., 2021)、Lang-Kihl和USBM (Siskind et al.,1980),其一般形式为 ...
Altitude effect of blasting vibration in slopes
0
2010
Retrieval of soil salinity content based on random forests regression optimized by Bayesian optimization algorithm and gentic algorithm
0
2021
Prediction of peak blasting velocity
0
2009
A novel hybrid surrogate intelligent model for creep index prediction based on particle swarm optimization and random forest
1
2020
... 为了评价本研究中混合模型的可靠性和准确性,通过模型评价指标决定系数(R2)、平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Square Error,RMSE)和中位数绝对误差(Median Absolute Error,MEDEA)的性能得分对模型性能进行对比评价(Zhang et al.,2020).这些评价指标用于描述PPV预测值与实测值之间的关系.R2表示实测值与预测值的线性相关性,MAE表示结果的偏差,RMSE表示结果的离散度,MEDEA表示结果的准确度.评价指标的计算公式如下: ...
Blasting vibration velocity prediction model based on RVM
0
2022
Predictive methods and influence factors of blasting vibration velocity
0
2012
Effects of minimum burden on deep-hole rock blasting block size
0
2016
基于随机森林和遥感的台风降水云光谱与降水关系研究
1
2022
... 近年来,越来越多的学者运用机器学习方法来探究爆破振动速度与其影响因素之间的非线性关系.BP神经网络适用于PPV预测,但基于BP神经网络建立起来的模型存在一定的缺陷,其自身存在过拟合以及初始权值和阈值的取值问题会使得预测结果出现不稳定等缺点(范勇等,2022);RVM的缺点是训练过程涉及到优化一个非凸的函数,且精度较SVM偏低(张研等,2022).而随机森林对多元共线性不敏感,预测结果对缺失数据和非平衡数据比较稳健(陈绎冰等,2022),且随机森林对训练样本要求不高.SMA算法具备良好的全局寻优能力(Lin et al.,2022),通过SMA算法准确优化随机森林的超参数可进一步提高预测的准确性.鉴于此,提出构建基于SMA算法优化随机森林的PPV预测模型. ...
基于改进PSO-BP神经网络的爆破振动速度峰值预测
2
2022
... 爆破是露天开采过程中的重要技术手段,除了要确保开挖岩土充分破碎外,还要保证爆破振动水平控制在一定范围内,以减少爆破对周围建筑和人员的危害(李萧翰等,2019).爆破振动质点速度峰值(Peak Particle Velocity,PPV)是衡量爆破振动对结构影响的重要指标.然而爆破振动质点速度受到爆破参数(如孔深、孔径、段药量、段间隔、爆破点和爆破持续时间等)、岩体性质参数(如岩体的纵波波速等)和地形地貌等众多因素的影响(Hu et al.,2018;范勇等,2022),而且这些因素之间存在复杂的非线性关系. ...
... 近年来,越来越多的学者运用机器学习方法来探究爆破振动速度与其影响因素之间的非线性关系.BP神经网络适用于PPV预测,但基于BP神经网络建立起来的模型存在一定的缺陷,其自身存在过拟合以及初始权值和阈值的取值问题会使得预测结果出现不稳定等缺点(范勇等,2022);RVM的缺点是训练过程涉及到优化一个非凸的函数,且精度较SVM偏低(张研等,2022).而随机森林对多元共线性不敏感,预测结果对缺失数据和非平衡数据比较稳健(陈绎冰等,2022),且随机森林对训练样本要求不高.SMA算法具备良好的全局寻优能力(Lin et al.,2022),通过SMA算法准确优化随机森林的超参数可进一步提高预测的准确性.鉴于此,提出构建基于SMA算法优化随机森林的PPV预测模型. ...
... 爆破是露天开采过程中的重要技术手段,除了要确保开挖岩土充分破碎外,还要保证爆破振动水平控制在一定范围内,以减少爆破对周围建筑和人员的危害(李萧翰等,2019).爆破振动质点速度峰值(Peak Particle Velocity,PPV)是衡量爆破振动对结构影响的重要指标.然而爆破振动质点速度受到爆破参数(如孔深、孔径、段药量、段间隔、爆破点和爆破持续时间等)、岩体性质参数(如岩体的纵波波速等)和地形地貌等众多因素的影响(Hu et al.,2018;范勇等,2022),而且这些因素之间存在复杂的非线性关系. ...
岩体质量分类的PCA-RF模型及应用
1
2018
... 随机森林是一种结合Bagging装袋法生成多个相互独立的分类和回归树(Classification and Regres-sion Tree,CART)进行分类和预测的集成算法(Brei-man,2001).主要原理是依靠结合多个决策树,并平均其结果使得决策树泛化误差收敛从而产生更好的预测结果(Lee et al.,2010).随机森林模型的原理是在CART决策树中使用Bagging算法在样本集进行有放回的抽样,抽取多个大小与原样本集相同的训练样本集,完成对集成模型的构建(图1).随机森林算法的思想是对遭受高方差的多棵决策树进行平均,从而构建一个具有更好泛化性能且更不容易出现过拟合且更稳健的模型.随机森林构建的基本步骤(Lee et al.,2010;刘强等,2018)如下: ...
... RF模型的预测精度和速度受树的个数和最小叶子点数等超参数的影响较大.当树的个数过少时模型容易欠拟合,而树的个数过多时既不能显著提升模型,又会增加模型的计算时间;同样随着最小叶子点数的增加,拟合效果会不断优化,同时模型的计算复杂度也会随之增加(杨练兵等,2021).因此,设置合适的树的个数和最小叶子点数显得尤为重要.SMA具有良好的全局优化能力和收敛性(Li et al.,2020),可以优化RF模型的超参数,从而提高其准确性.因此,本文提出了一种SMA-RF算法,该算法利用SMA优化RF的上述2个重要超参数,并将其应用于PPV预测. ...
... 近年来,越来越多的学者运用机器学习方法来探究爆破振动速度与其影响因素之间的非线性关系.BP神经网络适用于PPV预测,但基于BP神经网络建立起来的模型存在一定的缺陷,其自身存在过拟合以及初始权值和阈值的取值问题会使得预测结果出现不稳定等缺点(范勇等,2022);RVM的缺点是训练过程涉及到优化一个非凸的函数,且精度较SVM偏低(张研等,2022).而随机森林对多元共线性不敏感,预测结果对缺失数据和非平衡数据比较稳健(陈绎冰等,2022),且随机森林对训练样本要求不高.SMA算法具备良好的全局寻优能力(Lin et al.,2022),通过SMA算法准确优化随机森林的超参数可进一步提高预测的准确性.鉴于此,提出构建基于SMA算法优化随机森林的PPV预测模型. ...






 甘公网安备 62010202000672号
甘公网安备 62010202000672号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}