


招贤金矿床位于胶西北地区焦家断裂中段西部,矿区内岩浆岩分布广泛,岩性复杂多样。根据成矿环境及控矿因素分析,矿体受焦家断裂的破碎蚀变岩带控制,主要赋存在黄铁绢英岩化碎裂岩和花岗质碎裂岩带内(王英鹏等,2022)。不同岩性及其排列控制着岩石孔隙度和渗透率的分布模式,赋矿岩性的识别对于地质找矿工作具有一定的指示作用,了解岩性空间分布并提高岩性识别的准确率对于矿床成矿规律研究及找矿勘查具有重要指导意义。
针对测井响应特征与目标岩性之间的关系,学者们开展了大量研究,并运用多种方法进行了分析,如交会图法(赵建等,2003;徐德龙等,2012)、概率统计法(刘子云等,1989;孙健等,2009)和聚类分析法(寻知锋等,2008;Tian et al.,2016)等。上述方法在岩性识别领域取得了良好效果,但仍存在一些不足,如:交会图法难以充分利用测井曲线的信息且对复杂岩性识别率低,概率统计法可能会出现先验概率难以获得和人为因素影响较大的情况,而聚类分析法只有当训练样本无穷大时,才能保证其可行性。机器学习方法的发展为测井岩性识别提供了新的思路。近年来,机器学习技术已成为许多领域的研究热点,在测井解释中也得到了广泛应用,即将岩性识别视为一个分类问题,在复杂的岩性识别任务中引入了多种机器学习技术。常见的机器学习模型有支持向量机(SVM)(牟丹等,2015)、随机森林(RF)(康乾坤等,2020)和梯度提升树(GBDT)(Zou et al.,2021)等。快速发展的深度学习模型也被广泛应用于岩性识别,如人工神经网络(Ren et al.,2019)、深层信念网络和概率神经网络(Gu et al.,2019)、卷积神经网络(Zhu et al.,2018)、长短期记忆神经网络(LSTM)(He et al.,2023)和迁移学习(Dawson et al.,2023)等。此外,深度学习模型可与粒子群优化、数据增强、自适应等算法相结合,进一步增强模型预测性能和泛化性能(Liu et al.,2022;Jiang et al.,2022;张涛等,2023)。与其他机器学习算法相比,GBDT框架下的CatBoost算法采用CART(Classification and Regression Tree)技术,建立了一种有效的分割点选择机制,即特征选择。在实际应用中,有效的特征选择可以提高岩性识别精度(韩启迪等,2019)。
然而,上述算法很少考虑到岩性多样性的非均衡数据处理,尤其是小样本测井数据的复杂岩性识别。由于金属矿床地质条件复杂,钻孔获取的测井样本数据往往较少且分布不均匀,而岩性类别多样且分布差异较大,导致采集到的测井样本数据具有分布不平衡的特点(桂州等,2017),这种现象会影响机器学习方法的岩性分类识别结果。针对非均衡样本数据的处理,部分学者提出通过合成采样方法生成新的合成数据点以增加少数样本的数量,如:Chawla et al.(2002)提出了合成少数类样本过采样技术SMOTE。在SMOTE的启发下,研究人员开发了许多不同的合成采样方法,包括borderline-SMOTE(Hui et al.,2005)、SMOTE Tomek(Batista et al.,2004)和ADASYN(He et al.,2008)。其中,ADASYN算法能够根据少数类样本的空间分布构造新样本,适合非均衡小样本数据的处理。
因此,针对金属矿床复杂岩层分布的多样性和非均衡性,本研究基于ADASYN非均衡数据处理和CatBoost机器学习方法建立岩性分类模型,开展岩性智能识别方法与应用研究。以胶西北招贤金矿床实例测井数据为基础,选用ADASYN-CatBoost算法,针对10类岩性的样本数据,利用ADASYN算法对非均衡样本数据进行处理,采用CatBoost机器学习方法将其与10类岩性进行关联,建立优化的岩性分类模型,并与框架下的其他算法(GBDT,LightGBM)进行对比,进行实例岩性智能识别,为矿床复杂岩性的识别提供有效的技术手段。
1 ADASYN-CatBoost岩性分类识别方法
由于受地质条件和勘查技术的限制,金属矿测井获得的数据往往是小样本数据。针对分类样本数据不平衡的问题,本研究基于ADASYN过采样方法,在不破坏多数类样本结构的基础上,增加少数类样本的数量,使整个测井数据样本数量达到平衡,并将其作为机器学习分类算法的输入数据集。将平衡后的数据集随机选择80%作为训练集,20%作为测试集,并根据训练集数据和网格搜索对每个模型寻找最优参数组合建立分类模型。
ADASYN方法的基本思想是根据少数类样本的密度分布进行加权过采样,通过自适应生成合成样本(Xu et al.,2020;Liu et al.,2021),有效地针对难分类的少数类岩性数据生成更多的合成样本。CatBoost是一种改进的GBDT算法,该算法采用组合类别特征,有利于发掘测井特征之间的联系,提高岩性分类的精度(Vikrant et al.,2019)。基于ADASYN-CatBoost的测井岩性识别是在测井特征数据分析处理的基础上,通过ADASYN进行非均衡数据处理,利用CatBoost算法建立测井响应特征与岩性类别之间的非线性关系。测井岩性智能识别流程如图1所示。
图1
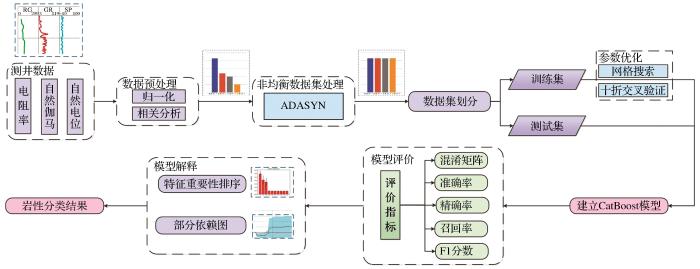
图1
面向非平衡测井数据的岩性智能识别流程图
Fig.1
Flow chart of intelligent lithology identification for unbalanced logging data
考虑到本研究针对的是小样本数据,因此将预处理后的数据随机划分为训练集(80%)和测试集(20%)。首先,基于训练集利用网格搜索结合十折交叉验证算法(Zhang et al.,2015;Zhao et al.,2019)进行参数寻优,网格搜索生成具有连续候选参数值的多维网格,再利用不同组合的可调参数对模型进行训练,通过十折交叉验证选择性能最优的超参数建立CatBoost岩性分类模型;然后,通过测试集上的准确率、精确率、召回率和F1分数等指标对模型性能进行评估;最后,借助特征重要性和部分依赖图进行模型解译,结合岩芯岩性资料对比验证,探索模型内在决策机制。
1.1 基于ADASYN的非平衡数据处理
ADASYN算法对于每个少数类样本,基于其k个最近邻样本中多数类样本的数量,采用SMOTE算法按比例创造新样本,为不同的少数类样本构造新样本(He et al.,2008),如图2所示。
图2
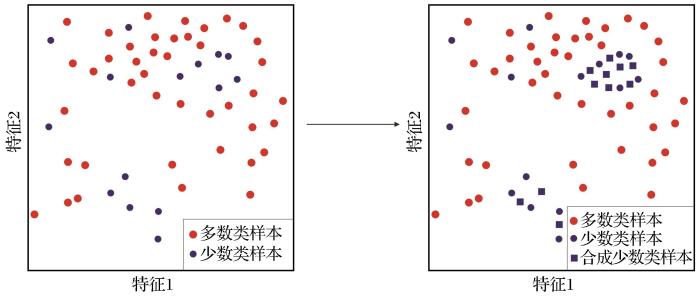
图2
ADASYN算法示意图(Elnahas et al.,2021)
Fig.2
Schematic diagram of ADASYN algorithm (Elnahas et al.,2021)
ADASYN算法步骤如下:对于给定训练集
Step 1:计算不平衡度
若
Step 2:计算需要合成的少数类样本数量
式中:
Step 3:对于每个小类样本
Step 4:对于每个少数类样本所对应的
Step 5:对于每个需要合成样本的少数类样本
为解决模型对于非均衡数据集中少数类样本学习能力不足的问题,ADASYN引入权重机制,根据少数类样本在原始数据集中的密度分布进行加权生成合成样本,少数类样本周围的多数类样本越多则合成少数类样本时的权重越大。通过ADASYN进行非均衡数据处理后少数类样本的数量增加,能够取得更好的模型分类效果。通过增强模型在少数类别样本上的学习效果,进一步改善模型对各种岩性的分类性能,从而提高岩性智能分类模型的学习能力。
1.2 CatBoost机器学习算法
CatBoost是在GBDT框架下提出的一种改良的Boosting算法。相比传统的GBDT算法,CatBoost考虑了特征之间的相互作用,并有效避免了模型的过拟合问题(张旭春,2021),主要从以下3个方面进行了改进。
(1)类别型特征的处理
类别型特征指类别特征不是数值型的,而是离散型的。对于给定训练集:
Step 1:对输入的样本集合随机排序,并生成多组随机排列;
Step 2:给定一个序列,针对每个例子,对于相同类别的例子计算其平均样本值;
Step 3:将所有的分类特征值转化为数值结果,方法如下:
记
式中:
通过对类别特征进行处理,CatBoost将包含类别型特征和数值型特征的训练集统一为数值型特征,增强模型对特征与目标变量之间非线性关系的学习能力。
(2)特征组合
CatBoost算法中,在树的第一次分割时,不考虑任何组合,但是在树的第二次分割时,会将树中所有的特征结合。通过对特征进行组合,CatBoost算法能够进一步学习特征之间的非线性关系,特征组合后可视为模型新的特征,利用特征之间的联系丰富了模型的特征维度,进一步表达数据的特性,提高岩性识别的准确性。在组合过程中,CatBoost支持对新组合的类别型特征进行转变,使其成为数值型特征。
(3)克服梯度偏差
由于传统的梯度提升算法在模拟模型的梯度时每一步都是基于相同的数据集来估计梯度,并基于此梯度进行训练得到基学习器,这种方法会使逐点梯度产生估计偏差,最终导致模型过拟合。
在克服梯度偏差处理中,CatBoost算法提出使用Ordered boosting方法改变传统算法中的梯度估计方式,CatBoost算法是通过对每个样本
CatBoost算法不仅提高了处理类别型特征的效率,而且获得的模型能够更好地避免过拟合现象的发生,使得最终得到的岩性识别模型更具有泛化性。因此,利用CatBoost分类器进行岩性识别,从而解决复杂地质条件下岩性与测井曲线之间的强非线性关系。
1.3 岩性分类识别评价方法
针对岩性分类问题,岩性识别结果最终被划分为4类:真正类(TP)、真负类(TN)、假正类(FP)和假负类(TN)(Tripathy et al.,2016)。在混淆矩阵的基础上,可以计算出准确率、精确率、召回率和F1分数。
本研究用准确率(Accuracy)表示所有预测正确的样本占总样本的比例,用精确率(Precision)表示正确预测为正类的样本占全部预测为正类的样本的比例,用召回率(Recall)表示正确预测为正类的样本占全部实际为正类的样本的比例。一个稳定的岩性智能识别模型应同时最大化地提高精确率和召回率,F1分数综合了精确率和召回率,因此F1分数也被选为重要的评估指标。最终通过岩芯岩性的比较,对分类结果进行验证,同时借助特征重要性分析和部分依赖图进行模型解译,探讨测井响应特征对岩性分类的影响。
在基于CART的集成模型中,特征重要性是通过平均每个决策树中每个特征的重要性来计算的。在本研究中,基尼系数被用作判断特征重要性的指数。可定义为
式中:
所有测井响应特征的总重要性等于100%,其值以相对方式来衡量。在CatBoost模型的训练过程中,每个特征都会根据其在建模中的重要性给出一个数值分数(Zheng et al.,2020;Wang et al.,2021),用来评估每个输入特征对目标变量的贡献。相对重要性越高,特征对预测函数的贡献就越大。每个测井响应特征的量化有助于增强模型的可解释性,以及更好地理解测井响应特征是如何影响岩性分类结果的。CatBoost模型可对每个测井特征的重要性进行评估和排序。
部分依赖图是一种用于黑盒机器学习模型输出的可视化技术,可以解释为预期目标响应作为“目标”特征的函数(Zhu et al.,2020),显示预测值如何随着输入变量的变化而变化。部分依赖图对可视化变量之间复杂类型的交互作用具有指示意义。本研究中采用部分依赖图显示岩性分类结果与测井响应特征之间的关系,将部分依赖函数(Friedman,2001)与CatBoost分类算法相结合,估计岩性识别对测井特征的部分依赖程度,用来解释黑盒模型(Elith et al.,2008)。
2 岩性识别实例分析
2.1 实例测井数据处理
本研究实例数据来源于胶西北招贤金矿床。胶西北招贤金矿床位于焦家断裂带中段西部,研究区岩性较为复杂(图3)。根据研究区钻孔柱状图,可将区内岩性细分为10种类别,主要岩性为胶东群片麻岩、二长花岗岩、钾化花岗质碎裂岩、绢英岩化花岗岩和黄铁绢英岩化花岗岩,其中黄铁绢英岩化花岗质碎裂岩和黄铁绢英岩化碎裂岩为赋矿岩性。
图3
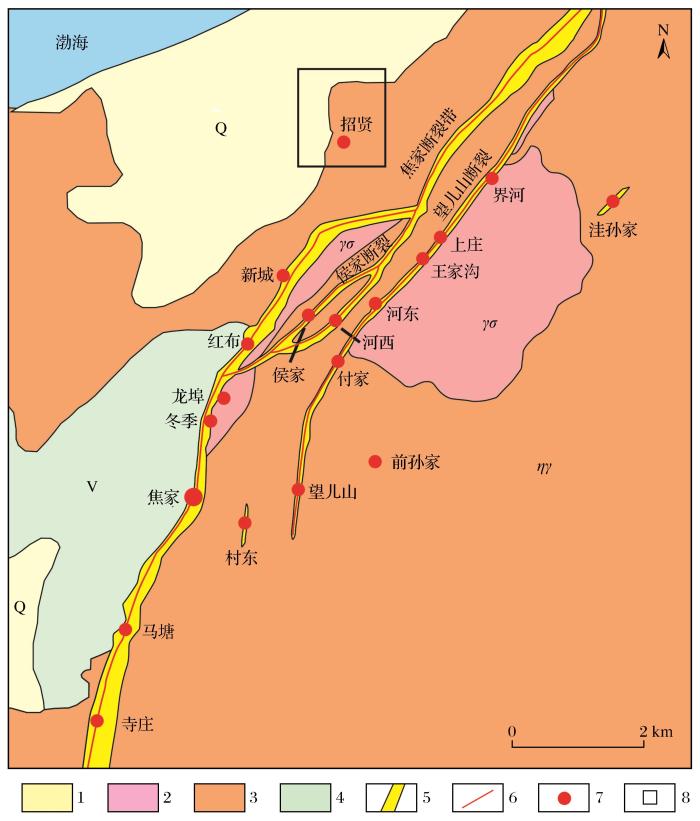
图3
胶西北招贤金矿床地质简图(修改自Yang et al.,2016)
1.第四系;2.郭家岭序列;3.玲珑序列;4.马连庄序列;5.破碎蚀变带;6.断裂;7.金矿床;8.研究区
Fig.3
Geological map of Zhaoxian gold deposit in Northwest Jiaodong (modified after Yang et al.,2016)
由于金属矿床地质构造复杂,不同岩性物理性质差异较大,考虑到不同岩石特征导致岩性的电阻率、自然伽马和自然电位特征差异显著,本研究选取电阻率、自然伽马和自然电位作为测井响应特征数据进行岩性识别,图4显示几种岩性对应的测井特征曲线。由于作者团队曾对该实例数据的归一化处理和相关性影响进行了分析(Zou et al.,2021),因此本文将不再复述,重点针对样本数据的不均衡性进行处理。
图4
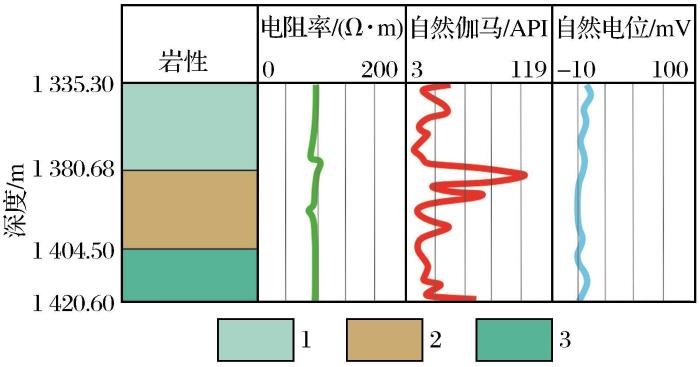
图4
测井曲线和观察的岩性
1.黄铁绢英岩化花岗质碎裂岩;2.绢英岩化花岗质碎裂岩;3.钾化绢英岩化花岗质碎裂岩
Fig.4
Logging curves and observed lithology
表1 部分测井数据训练集
Table 1
| 电阻率/(Ω·m) | 自然伽马/API | 自然电位/mV | 岩性 | 编码 |
|---|---|---|---|---|
| 84.6 | 30.8 | 23.04 | 钾化绢英岩化花岗质碎裂岩 | 10 |
| 79.2 | 54.6 | 23.10 | 黄铁绢英岩化碎裂岩 | 9 |
| 90 | 53.2 | 6.09 | 绢英岩化花岗质碎裂岩 | 4 |
| 76.5 | 40.6 | 13.94 | 绢英岩化花岗岩 | 6 |
| 99 | 23.8 | 27.70 | 中粒含黑云二长花岗岩 | 3 |
| ︙ | ︙ | ︙ | ︙ | ︙ |
| 94.5 | 43.4 | 19.03 | 含黑云二长花岗岩 | 7 |
| 83.7 | 32.2 | 16.97 | 钾化绢英岩化花岗质碎裂岩 | 10 |
| 1 584.9 | 39.2 | 4.74 | 钾化花岗质碎裂岩 | 2 |
| 75.6 | 39.2 | 12.01 | 绢英岩化花岗岩 | 6 |
| 93.6 | 54.6 | 21.97 | 中粒含黑云二长花岗岩 | 3 |
表2 实例测井数据中各岩性类别对应的样本统计
Table 2
| 岩性 | 类别 | 样本数/个 | |
|---|---|---|---|
| 处理前 | ADASYN处理后 | ||
| 总计 | 2 609 | 10 540 | |
| 含角闪黑云英云闪长岩质片麻岩 | 1 | 83 | 1 047 |
| 钾化花岗质碎裂岩 | 2 | 173 | 1 038 |
| 中粒含黑云二长花岗岩 | 3 | 1 045 | 1 045 |
| 绢英岩化花岗质碎裂岩 | 4 | 570 | 1 094 |
| 钾化含黑云二长花岗岩 | 5 | 27 | 1 047 |
| 绢英岩化花岗岩 | 6 | 217 | 1 038 |
| 含黑云二长花岗岩 | 7 | 140 | 1 072 |
| 黄铁绢英岩化花岗质碎裂岩 | 8 | 149 | 1 073 |
| 黄铁绢英岩化碎裂岩 | 9 | 80 | 1 050 |
| 钾化绢英岩化花岗质碎裂岩 | 10 | 125 | 1 036 |
由表2可知,不同岩性对应的样本数目很不均衡,如钾化含黑云二长花岗岩(第5类)的样本量过小,易导致测井响应特征及岩性不能完全拟合,会影响机器学习的岩性分类识别结果,因此需针对数据的非均衡性进行有效处理。考虑本研究的实例数据为小样本数据,在数据归一化和特征相关性分析的基础上,采用ADASYN方法进行处理。经过处理后的数据中各岩性类别的样本数目达到均衡,共有10 540条数据。
2.2 岩性识别模型构建与评价
采用CatBoost算法建立测井响应特征和岩性类别之间的非线性关系,算法通过Python编程实现。在建立机器学习模型的过程中,利用验证曲线确定参数区间,然后采用网格搜索算法结合十折交叉验证算法进行参数调优,得到各模型的最优超参数。
图5所示为CatBoost算法验证曲线,可见学习率(learning_rate)、树的深度(depth)、最大迭代次数(iterations)和L2正则化参数(l2_leaf_reg)的网格搜索范围。在模型分数最高的点附近设置搜索区间,采用网格搜索对模型最优参数组合进行寻找,确定该参数组合为最优参数组合,得到最佳参数组合为0.1、10、300和1,交叉验证准确率为92.31%。表3同时显示GBDT、XGBoost和LightGBM模型的最佳参数。其中,GBDT模型中对学习率(learning_rate)、弱学习器个数(n_estimators)、叶子节点最小样本数(min_samples_leaf)和树的最大深度(max_depth)进行参数调优,LightGBM模型中对学习率(learning_rate)、弱学习器的个数(n_estimators)、树最大深度(max_depth)、树的叶子节点个数(num_leaves)和叶子节点最小数据量(min_data_in_leaf)进行调优。
图5
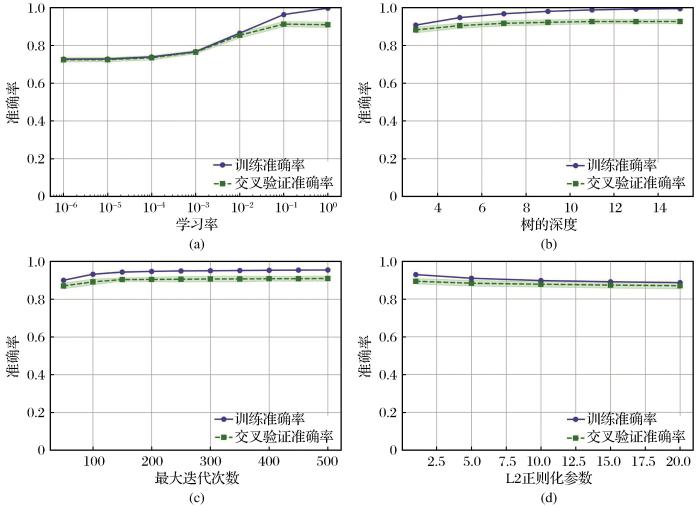
表3 模型的超参数数值范围及其最优解
Table 3
| 分类器 | 超参数 | 搜索范围 | 最优参数 |
|---|---|---|---|
| GBDT | 学习率 | 0.000001~0.5 | 0.1 |
| 弱学习器个数 | 50~130 | 119 | |
| 叶子节点最小样本数 | 5~50 | 10 | |
| 树的最大深度 | 2~30 | 25 | |
| LightGBM | 学习率 | 0.001~0.800 | 0.2 |
| 弱学习器个数 | 50~130 | 102 | |
| 树的最大深度 | 1~50 | 24 | |
| 树的叶子节点个数 | 15~60 | 46 | |
| 叶子节点最小数据量 | 5~55 | 30 | |
| CatBoost | 学习率 | 0.001~0.800 | 0.1 |
| 树的深度 | 3~17 | 10 | |
| 最大迭代次数 | 50~500 | 300 | |
| L2正则化参数 | 1~20 | 1 |
为了验证采用ADASYN进行非均衡样本数据处理的效果,比较样本数据均衡化处理对分类模型的影响,将基于ADASYN方法数据处理后建立的ADASYN-GBDT、ADASYN-LightGBM和ADASYN-CatBoost岩性分类模型与针对每种算法未考虑非均衡数据处理建立的模型进行比较。图6所示为上述几种分类模型在训练集和测试集上的准确率。由图6可知,岩性分类模型的测试性能与训练性能接近,验证了测试集分类结果的有效性。表4为几种模型在测试集上的准确率、召回率和F1分数。结果表明,ADASYN-CatBoost模型的岩性分类性能优于其他分类模型,准确率、召回率和F1分数分别达到0.9821、0.9820和0.9820,模型评价排序依次为ADASYN-CatBoost>ADASYN-LightGBM>ADASYN-GBDT>CatBoost>LightGBM>GBDT。分析结果表明,经过样本数据均衡化处理后,6种模型的准确率均得到提升,在本实例中,ADASYN-CatBoost模型是岩性识别最有效的方法,更加有利于测井解释。
图6
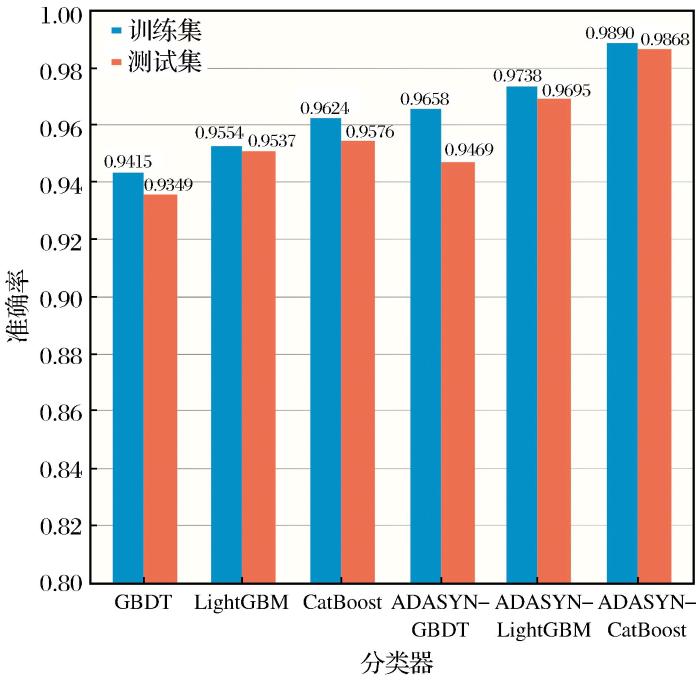
图6
几种模型训练集和测试集的准确率对比
Fig.6
Comparison of accuracy of the training and test sets of several models
表4 测试集上岩性识别精确率、召回率和F1分数(加权平均)
Table 4
| 分类器 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|
| GBDT | 0.9355 | 0.9349 | 0.9327 |
| LightGBM | 0.9561 | 0.9554 | 0.9552 |
| CatBoost | 0.9503 | 0.9600 | 0.9600 |
| ADASYN-GBDT | 0.9472 | 0.9469 | 0.9466 |
| ADASYN-LightGBM | 0.9695 | 0.9695 | 0.9695 |
| ADASYN-CatBoost | 0.9821 | 0.9820 | 0.9820 |
经过ADASYN处理之后建立的6种岩性分类器的混淆矩阵如图7所示,其中对角线为每个岩性类别中被正确分类的比例。结果显示,ADASYN-CatBoost分类器的岩性识别性能明显高于其他分类器。在5个分类器中,ADASYN-CatBoost分类器的性能最佳,该方法成功地从测井资料中识别了至少98.5%的岩性,取得理想的分类效果。
图7
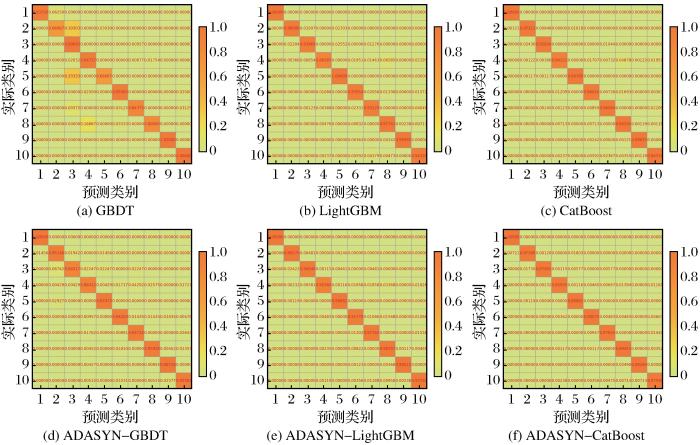
图7
测试集的岩性识别混淆矩阵图
Fig.7
Confusion matrix diagram of lithology identification of test set
2.3 结果验证与解译分析
将4种分类器得到的岩性识别结果与岩心岩性进行对比(图8),进一步验证了几种分类器岩性分类识别结果的有效性。由图8可知,所有模型均可根据测井响应的差异区分10种岩性,但根据岩芯的厚度,区分稍有差异。对于所有岩性,ADASYN-CatBoost的岩性识别结果与岩芯资料的一致性最佳,ADASYN-CatBoost分类器在识别黄铁绢英岩化花岗质碎裂岩(第8类)和黄铁绢英岩化碎裂岩(第9类)时,其效果优于其他分类器。分析原因可能如下:(1)CatBoost模型通过迭代学习方法根据预测的岩性调整权重,提高了预测精度;(2)与其他分类器相比,CatBoost模型自动对一些离散特征进行组合,生成内部特征作为模型的训练,提高了岩性分类的效率。
图8
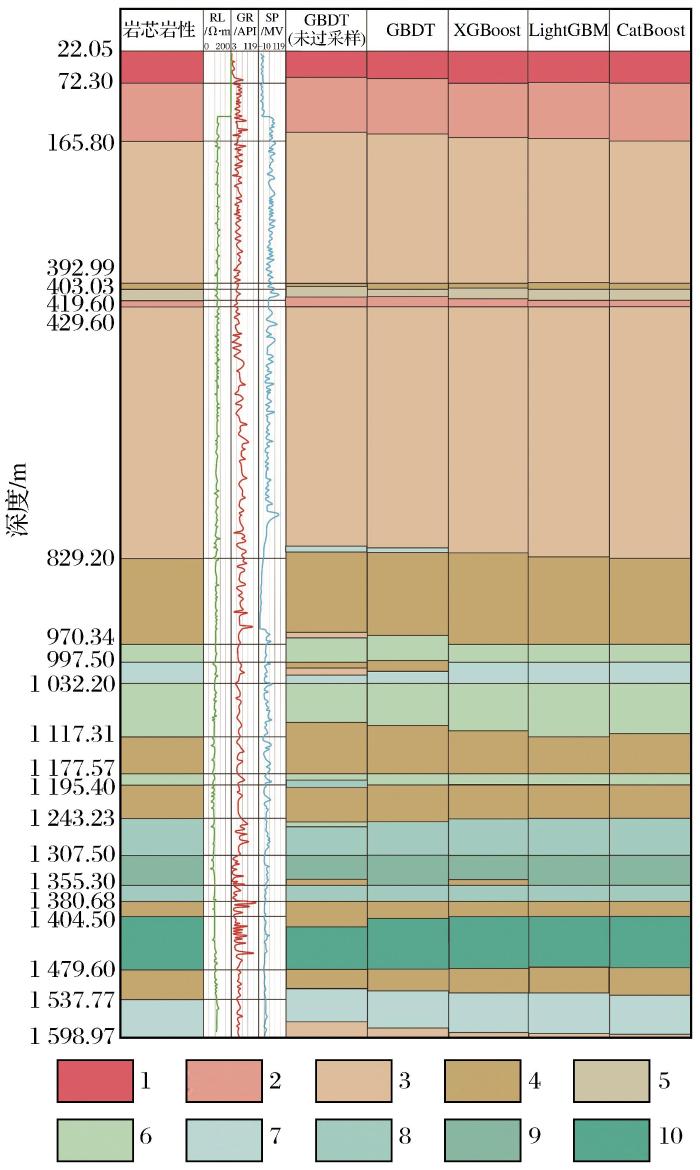
图8
岩性识别结果验证图
1.含角闪黑云英云闪长岩质片麻岩;2.钾化花岗质碎裂岩;3.中粒含黑云二长花岗岩;4.绢英岩化花岗质碎裂岩;5.钾化含黑云二长花岗岩;6.绢英岩化花岗岩;7.含黑云二长花岗岩;8.黄铁绢英岩化花岗质碎裂岩;9.黄铁绢英岩化碎裂岩;10.钾化绢英岩化花岗质碎裂岩
Fig.8
Verification diagram of lithological identification
results
分析CatBoost模型的特征重要性排序(表5),结果表明3个测井响应特征对岩性分类贡献的重要性排序依次为电阻率测井(RL)、自然电位测井(SP)和自然伽马测井(GR)。特征重要性排序体现了电阻率、自然伽马和自然电位参数对岩石岩性的综合响应与区分,实例研究结果表明特征重要性排序与研究区的主要岩性及其分布特点密切相关。从研究区岩性分布来看,10种岩性电阻率特征存在显著差异,而断裂带和接触带中的部分岩层与其他致密岩层自然电位特征的区别较为显著,只有少部分岩性的放射性元素含量及自然伽马特征变化较大。具体分析如下:
表5 CatBoost模型的特征重要性排序结果
Table 5
| 排序 | 特征 | CatBoost |
|---|---|---|
| 1 | 电阻率测井 | 52.4% |
| 2 | 自然电位测井 | 28.9% |
| 3 | 自然伽马测井 | 18.7% |
(1)电阻率作为最重要的测井响应特征,能够有效捕获电阻率异常,最大程度地区分研究区内具有不同电阻特征的岩石岩性、结构和构造差异。这与研究区内分布有高阻特征的二长花岗岩和花岗闪长岩,高中阻特征的蚀变花岗岩,低阻带中局部高阻特征的蚀变带,以及具有最低阻特征的变辉长岩和黑云母片岩有关。
(2)自然电位通常是由于离子扩散和吸附作用产生的,氧化还原反应和压差也会导致自然电位。一般而言,研究区断裂带和接触带等岩层富水位置会堆积正离子,致密的岩石等贫水位置会堆积负离子,可通过自然电位测井进行识别。
(3)不同岩石中放射性元素的含量存在一定的差异,进而导致其自然伽马不同。由于自然伽马的抗干扰性能强,因此可以利用这一特征划分岩性。根据放射性强度能够区分出研究区整体强度低的片麻岩,强度较高且曲线平稳的二长花岗岩,而黄铁绢英岩化花岗岩自然伽马曲线受蚀变影响,整体偏低,但起伏较大且变化剧烈,也容易区分。
部分依赖图显示单一特征或特征组合如何影响模型的分类性能。以赋存矿体的黄铁绢英岩化花岗质碎裂岩(类别8)为例,图9显示该类的部分依赖图,大于0表示“属于该类”,小于0表示“不属于该类”,数值大小表示对划分为该类的贡献程度。由图9可知:(1)电阻率测井值越大,对划分为黄铁绢英岩化花岗质碎裂岩(类别8)的贡献越大。当电阻率测井增加至79 Ω·m时,继续增加电阻率测井值对岩性分类贡献不大。(2)自然电位测井值越大,对划分为类别8的贡献越大。当自然电位测井值增加至15 mV时,继续增加自然电位测井值对岩性分类贡献不大。当自然电位测井值从18 mV增加至20 mV时,对岩性分类的贡献先减小后增大。当自然电位测井值达到20 mV时,继续增加自然电位测井值对岩性分类的贡献不再有效。(3)自然伽马测井值越大,对划分为类别8的贡献越大。当自然伽马测井值增加至22 API时,继续增加自然伽马测井值对岩性分类贡献不大。
图9
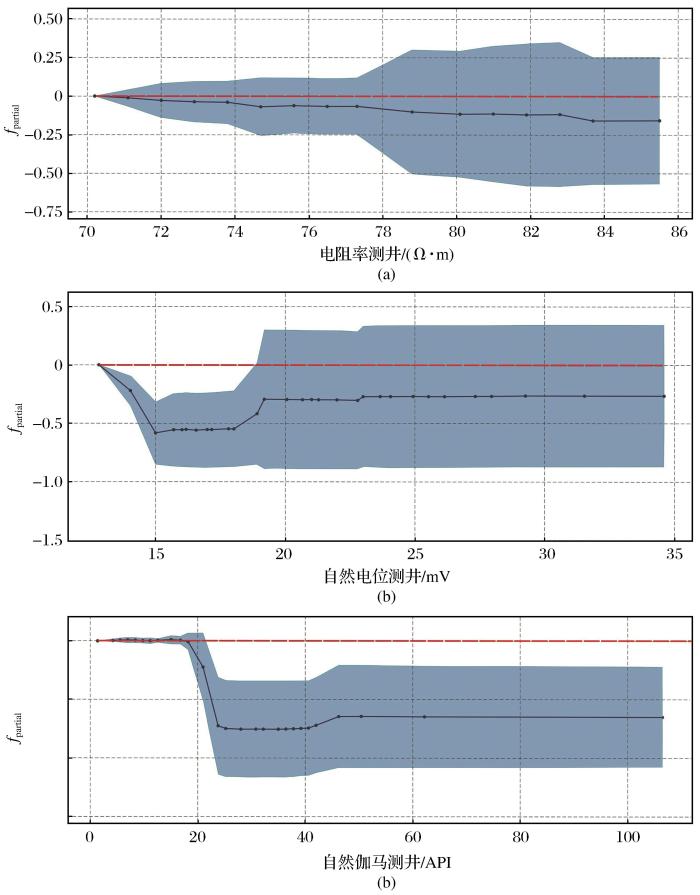
图9
单个测井特征与岩性的部分依赖图
Fig.9
Partial dependence diagram of single logging characteristics and lithology
图10为2个特征的任意组合对分类结果的影响。当电阻率测井值小于76 Ω·m,自然伽马测井值低于20 API时,模型的分类性能最佳。同样,当自然伽马测井值低于20 API,自然电位测井值高于20 mV时,该模型具有良好的识别效果。此外,当电阻率测井值小于74 Ω·m,自然电位测井值低于12 mV时,该模型预测岩性最有效。由图10可以直观地了解测井特征如何影响岩性识别的性能。基于本文所建模型,能够有效提高分类性能,为地质工作者进行岩性识别提供了有效方法。图9和图10为识别黄铁绢英岩化花岗质碎裂岩(第8类)提供了有利的测井组合,提供了岩性识别集成模型的可解释性,这将使地质学家能够对岩性识别结果进行深入评估,并对招贤金矿研究区获得新的见解。
图10
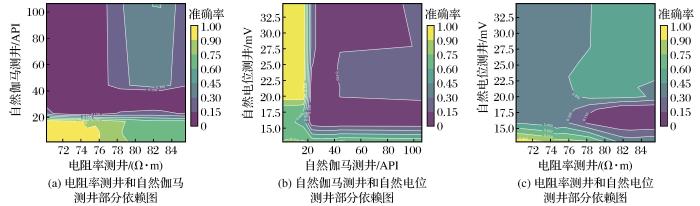
图10
测井特征组合与岩性的部分依赖图
Fig.10
Partial dependence diagram of logging feature combination and lithology
3 结论
考虑到测井响应特征与岩性之间的强非线性关系,在非平衡样本数据处理基础上研究基于机器学习算法的测井岩性智能识别方法与流程,并以胶西北招贤金矿床实例测井数据为例,针对非平衡的样本数据,进行ADASYN过采样后构建了CatBoost岩性识别模型。得出如下结论:
(1)针对实例研究区复杂岩性分布和非均衡测井样本数据,提出了一套基于ADASYN非均衡数据处理和CatBoost机器学习的测井岩性智能识别方法与流程。该方法首先利用ADASYN算法处理非均衡测井样本数据,针对难分类的少数类样本数据生成合成样本,然后采用CatBoost算法结合网格搜索十折交叉验证构建最优岩性分类识别模型,通过增强模型在少数类样本上的学习效果进一步改善模型的岩性分类性能,结果显示通过ASASYN算法进行数据处理后,模型岩性识别的精度明显提高了。
(2)基于ADASYN-CatBoost方法针对实例矿床10种岩性进行智能识别,建立岩性分类模型,取得了良好的岩性识别效果。在ADASYN算法数据处理的基础上,结合CatBoost机器学习方法实现了实例研究区10种岩性的分类识别。模型评价结果显示,ADASYN-CatBoost方法对实例矿床岩性识别具有良好的分类性能,平均精确率为98.21%,召回率为98.20%,F1分数为98.20%,尤其针对黄铁绢英岩化花岗质碎裂岩和黄铁绢英岩化碎裂岩2种赋矿岩性,取得了较好的分类识别效果。
(3)结合测井响应特征的重要性贡献排序解译CatBoost模型内在决策机制,增强了模型分类岩性识别的可解释性,分析特征的贡献排序与研究区主要岩性及其分布特点密切相关。实例CatBoost模型解译结果表明,特征贡献排序分别为电阻率、自然电位和自然伽马,采用部分依赖图进一步显示岩性分类结果与测井响应特征之间的关系,估计岩性识别对测井特征的部分依赖程度,提高了岩性识别模型的可解释性。结果显示,CatBoost模型具有强稳健性、强泛化能力、强解释性和强分类性能,对进一步开展实例矿床深部矿产资源勘探具有重要的指示意义。
下一步工作的重点是将本文所提方法应用于其他地质情况类似的矿区,进一步验证该方法预测的准确度。由于本研究中不同岩性对应的样本数目较少且很不均衡,所以对全部样本进行了均衡化处理,并未考虑均衡化对测试集结果造成的影响。在后续工作中,将考虑先划分数据集,使用均衡化处理后的训练集训练模型,尽量保持测试集样本的真实性,对已训练的模型进行评估,获得模型在真实样本分布下的性能指标。
http://www.goldsci.ac.cn/article/2023/1005-2518/1005-2518-2023-31-5-721.shtml
参考文献
A study of the behavior of several methods for balancing machine learning training data
[J].
L O,
et al,2002.SMOTE:Synthetic minority over-sampling technique[J].
Application of convolutional neural network in lithology identification
[J].
Impact of dataset size and convolutional neural network architecture on transfer learning for carbonate rock classification
[J].
A working guide to boosted regression trees
[J].
Imbalanced data over-sampling technique based on convex combination method
[J].
Greedy function approximation: A gradient boosting machine
[J].
Current status and progress of lithology identification technology
[J].
Intelligent measurement on geometric information of rock discontinuities based on borehole image
[J].
Complex lithology prediction using probabilistic neural network improved by continuous restricted Boltzmann machine and particle swarm optimization
[J].
Classification of imbalance geological data based on PCA-SMOTE algorithm and random forest:A case study of geochemical data from the eastern Tianshan of China
[J].
Application of support vector machine based on decision tree feature extraction in lithology classification
[J].
ADASYN:Adaptive synthetic sampling approach for imbalanced learning
[C]//
Lithologic identification of complex reservoir based on PSO-LSTM-FCN algorithm
[J].
Borderline-SMOTE:A new over-sampling method in imbalanced data sets learning
[C]//
Adaptive multiexpert learning for lithology recognition
[J].
Application of random forest algorithm in classification of logging lithology
[J].
A fast network intrusion detection system using adaptive synthetic oversampling and LightGBM
[J].
Determination of lithology through probability statistics
[J].
Integrating deep learning and logging data analytics for lithofacies classification and 3D modeling of tight sandstone reservoirs
[J].
Review on advancement in technology and equipment of geophysical exploration for metallic deposits in China
[J].
Lithological identification of volcanic rocks from SVM well logging data:Case study in the eastern depression of Liaohe Basin
[J].
Lithology identification using well logs:A method by integrating artificial neural networks and sedimentary patterns
[J].
Bayes discriminant analysis method in lithology recognition
[J].
Multi-resolution graph-based clustering analysis for lithofacies identification from well log data:Case study of intraplatform bank gas fields,Amu Darya Basin
[J].
Classification of sentiment reviews using n-gram machine learning approach
[J].
Formation lithology classification using scalable gradient boosted decision trees
[J].
Study of connectivity of discontinuities of borehole based on digital borehole images
[J].
Lithology identification method based on gradient boosting algorithm
[J].
Aircraft taxi time prediction:Feature importance and their implications
[J].
Geological significances and geochemical compositions of gold and gold-bearing minerals from Zhaoxian deeply-seated gold deposit,Jiaodong area
[J].
Research on the identification of the lithology and fluid type of foreign oilfield by using the crossplot method
[J].
A predictive model of recreational water quality based on adaptive synthetic sampling algorithms and machine learning
[J].
The application of cluster and discriminant analyses in logging lithology recognition
[J].
Origin and evolution of ore fluid,and gold-deposition processes at the giant Taishang gold deposit,Jiaodong Peninsula,Eastern China
[J].
Identification of cuttings based on color and texture feature
[J].
Comparisons of isomiR patterns and classification performance using the rank-based MANOVA and 10-fold cross-validation
[J].
Lithology interpretation of deep metamorphic rocks with well logging based on APSO-LSSVM algorithm
[J].
Based on the CatBoost Model to Realize Monitoring and Early Warning for Discharge Situation of the Sewage Treatment Plant
[D].
Application of crossplots based on well log data in identifying volcanic lithology
[J].
Averaging estimators for discrete choice by M-fold cross-validation
[J].
A review of lithology interpretation methods using geophysical well logs
[J].
GSSA:Pay attention to graph feature importance for GCN via statistical self-attention
[J].
Intelligent logging lithological interpretation with convolution neural networks
[J].
Machine learning for the selection of carbon-based materials for tetracycline and sulfamethoxazole adsorption
[J].
Gradient boosting decision tree for lithology identification with well logs:A case study of Zhaoxian gold deposit,Shandong Peninsula,China
[J].
卷积神经网络在岩性识别中的应用
[J].
岩性识别技术现状与进展
[J].
基于钻孔图像的岩体结构面几何信息智能测量
[J].
基于PCA-SMOTE-随机森林的地质不平衡数据分类方法——以东天山地球化学数据为例
[J].
基于决策树特征提取的支持向量机在岩性分类中的应用
[J].
随机森林算法在测井岩性分类中的应用
[J].
利用概率统计方法判断岩性
[J].
金属矿地球物理勘探技术与设备:回顾与进展
[J].
基于SVM测井数据的火山岩岩性识别——以辽河盆地东部坳陷为例
[J].
Bayes判别分析方法在岩性识别中的应用
[J].
基于数字钻孔图像的结构面连通性研究
[J].
基于梯度提升算法的岩性识别方法
[J].
胶东地区招贤深部金矿床金和载金矿物化学成分及其地质意义
[J].
利用交会图法识别国外M油田岩性与流体类型的研究
[J].
聚类和判别分析在测井岩性识别中的应用
[J].
基于颜色特征和纹理特征的岩屑岩性识别
[J].
基于自适应粒子群优化最小二乘支持向量机的深层变质岩测井岩性识别
[J].
基于CatBoost模型实现对污水处理厂排污情况的监测预警
[D].
测井资料交会图法在火山岩岩性识别中的应用
[J].
地球物理测井岩性解释方法综述
[J].


 甘公网安备 62010202000672号
甘公网安备 62010202000672号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}