



岩体质量分级方法主要有单指标分级、多指标综合分级和系统工程分级3种。其中,单指标分级方法主要有Terzaghi岩体载荷指标分级、普氏系数法、弹性波速法和RQD法等。此类方法简单,主要考虑岩体单一属性的认识,但忽略了地下工程的复杂性,导致评价结果与实际情况之间存在较大差异。多指标综合分级方法包括Q系统分级法(Barton et al.,1981;Barton,2002)、RMR分级法(Bieniawski,1978)和BQ分级法(中华人民共和国水利部,2014)等。此类方法考虑了岩体强度、地质环境和自身软弱结构面等因素的影响,能够较好地反映工程地质特征,在实际工程中得到了广泛应用。但是,多指标综合分级方法的不足是评价指标易受主观因素的影响。随着系统工程方法的发展,在多指标分级基础上引入系统工程理论,通过距离判别分析法、可拓评判方法、动态权重法、多维云模型和粗糙集理论等方法(宫凤强等,2007;文畅平,2008;原国红等,2005;Tu et al.,2019),建立岩体质量评价模型,充分考虑了岩体质量分级的模糊性,打破了指标选取的局限性,避免了评价过程中的主观性,评价结果达到较高的预测精度,更加贴近工程实际。同时,在对系统工程评价方法进行优化改进的基础上,建立了模糊RES-多维云分级模型(周坦等,2019)、RS-TOPSIS模型(胡建华等,2012)、改进分类区分度及权重的灰评估模型(周述达等,2016)以及有限区间云模型和距离判别赋权结合的模型,改进了岩体质量分级传统模型的缺陷,丰富了岩体质量分级评价方法的理论研究和工程应用。
随着计算机计算能力的提高,人工智能算法在岩体质量分级领域得到了广泛应用,在获得足够多的已标注样本,以及学习样本和测试样本同源且独立同分布的条件下,神经网络(杨朝晖等,1999;陈星,2018)和支持向量机(何云松等,2017;Zheng et al.,2020)等大量先验数据的智能分级取得了良好效果。但在实际中同一区域满足条件的学习样本数量一般较少,此时训练出的模型会出现预测精度低或过拟合等问题。迁移学习可以利用任务之间的相关性,将已有的知识进行迁移,用于求解相关领域的问题,很好地解决了传统机器学习方法中训练样本少、训练模型困难的问题,目前应用较为广泛的迁移学习方法是由Dai et al.(2007)提出的TrAdaBoost算法。徐桂芝等(2019)、刘万军等(2018)和Qin et al.(2019)将TrAdaBoost算法用于分类学习,证明了在样本数量较少的情况下,TrAdaBoost算法的正确率高于传统的机器学习算法。TrAdaBoost算法扩大了训练样本容量,在一定程度上提高了模型预测精度和泛化能力,但该方法在应用中仍存在源领域权重下降过快、产生负迁移现象的可能性和多分类问题求解复杂等问题。针对以上问题,采用孤立森林(Isolation Forest)对两阶段迁移学习算法(Two-stage TrAdaBoost.R2)进行改进,建立基于改进迁移学习的岩体质量分级模型,组建多源数据库对模型进行训练,案例验证了模型的有效性。
1 迁移学习基本原理
1.1 迁移学习模型
TrAdaBoost算法(Dai et al.,2007)通过调整样本权重来实现迁移过程,要求源领域样本与目标领域样本的特征分布相似。在训练基本学习器时,TrAdaBoost算法对源领域样本权重和目标领域样本权重采用2种不同的调整机制(图1)。在源领域中,采用加权多数算法(Weighted Majority Algorithm,WMA)进行样本权重调整,提高其中与目标领域相似度高的样本权重,降低相似度较低的样本权重,使源领域中有利于目标领域学习的样本发挥更大作用,同时降低坏样本对模型训练的影响。在目标领域中,采用AdaBoost调整机制,认为被错误分类的样本是难分类的,被正确分类的样本是容易分类的,通过提高目标领域中被错误分类的样本权重,降低被正确分类的样本权重,使分类器在下一次迭代过程中更加关注难分类的样本。
图1
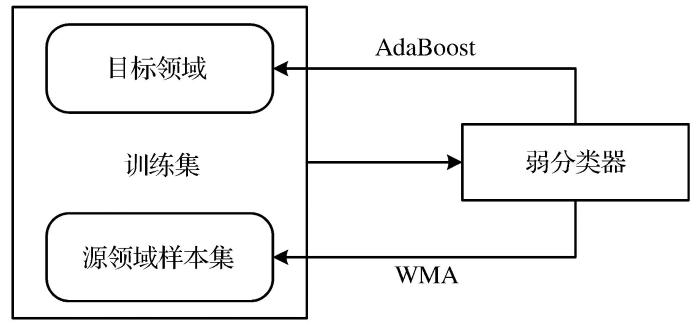
TrAdaboost算法是以Boosting思想为基础的集成算法,其原理是通过训练多个基本学习器,将其以一定的方法组合,从而形成一个强学习器。在计算过程中,只要基本学习器的性能高于随机猜想,则该学习器就是可用的。将准确率高的基本学习器赋予较高的权重,准确率低的基本学习器赋予较低的权重,由此得到的集成学习器相比单一学习器能够达到更好的效果。
1.2 迁移学习模型改进
(1)多分类问题
根据输出变量类型的不同,将监督学习划分为分类问题和回归问题。其中,分类算法输出的结果是离散的,对输入数据进行定性判断;回归算法输出的结果是连续的,对输入数据进行定量预测。
TrAdaBoost算法的基本学习器为分类树,是一种分类结果为(0,1)的二分类算法。将该算法用于求解多分类问题时,通常将多分类问题分解为多个二分类问题,使用多个分类器来完成。当需要输出的类别较多时,这种分类方法非常消耗计算机资源。如将岩体质量划分为5个等级,在训练模型时,可按照如图2所示的方法,将多分类问题划分为4个二分类问题,进行逐级分类,最终实现岩体质量5个等级的划分。
图2
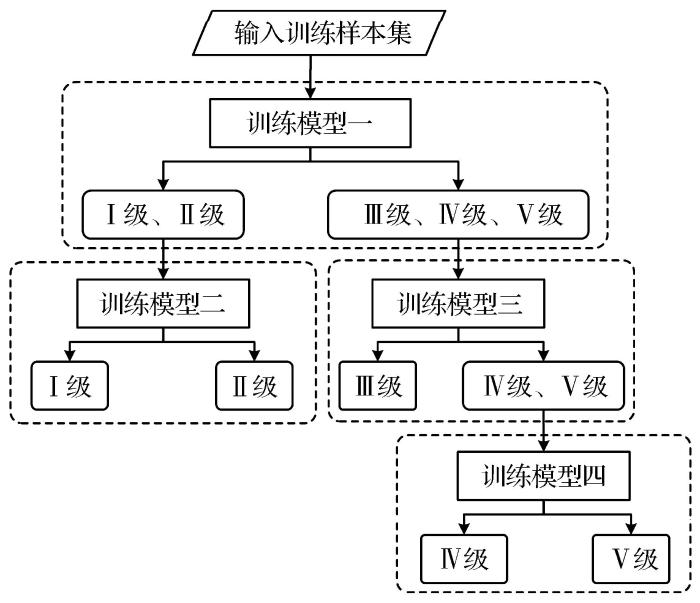
在利用迁移学习算法进行岩体质量等级划分时,可将原本的多分类问题转化为回归问题,在改进的迁移学习算法中,采用回归算法对岩体质量等级进行预测,仅需一个模型即可实现样本多个等级的判断,克服了分类算法在解决多分类问题时的局限性。
(2)孤立森林算法
迁移学习要求源领域数据与目标领域数据的分布特征相似,若源领域中存在孤立的异常点,而将其迁移到目标领域中时,将会导致模型的精度降低,出现负迁移现象。因此,在模型训练之前对源领域样本进行过滤,可以有效防止负迁移现象的发生。
在数据的特征空间内,异常点所占比例较小,其特征值往往与正常点的特征值相差较大,如果某些点分布稀疏且远离群体,可认为这些点是发生概率较低的异常点。
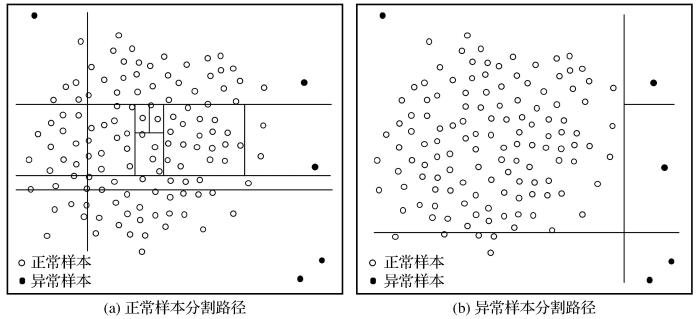
孤立森林算法(Liu et al.,2012)是一种无监督的异常检测方法,可以检测出大量数据中与其他数据规律不一致的异常点。其原理是通过递归地随机分割数据集,直到特征空间内所有的点均被孤立。在样本集中,那些异常的离群点分割路径往往较短,通过较少的次数就可以被孤立,而正常点往往需要多次划分才能被孤立,如图3所示,通过对比样本的路径长度,可以将异常点筛选出来。通过筛选和过滤异常数据,降低其对模型的影响,能够在一定程度上提高模型的预测精度。
图3
(3)两阶段迁移学习
为了解决TrAdaBoost算法源领域权重下降过快的问题,Pardoe et al.(2010)提出了一种两阶段迁移学习方法(Two-stage TrAdaBoost.R2)。该算法在每次循环内,均通过两阶段调整样本权重。第一阶段,源领域样本权重相对不变,仅改变目标领域样本权重;第二阶段,目标领域样本权重相对不变,仅改变源领域样本权重。在每阶段样本权重调整后,需对其进行标准化处理,保证源领域样本和目标领域样本的总权重为1。算法流程如图4所示。
图4
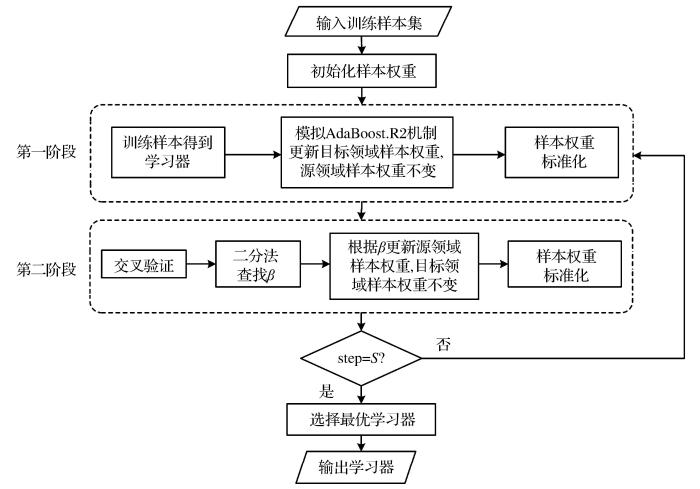
在第一阶段,源领域样本权重不变,目标领域根据TrAdaBoost.R2的权重调整机制更新,即提高被错误分类的样本权重,降低被正确分类的样本权重。第一阶段的样本权重按照下式进行更新:
目标领域的权重辅助更新参数
式中:前n个样本来自于源领域,后m个样本来自于目标领域;
第二阶段样本权重在第一阶段的基础上进行调整,目标领域样本权重不变,源领域样本权重均匀减小。第二阶段的样本权重按照下式进行更新:
源领域的权重辅助更新参数
该算法在每次循环结束后,仅保存第二阶段的权重更新结果作为下一循环的初始权重,解决了TrAdaBoost算法中源领域权重下降过快的问题。
(4)预测精度评价
模型的预测精度采用均方误差(MSE)进行评价,均方误差是指预测值与真实值之差平方的期望值,计算公式如下:
式中:
均方误差可表示实际输出值与期望输出值之间的偏差,MSE值越小,说明预测模型具有更好的精度,模型的评价效果越好。
2 岩体质量分级模型构建
2.1 岩体质量分级指标
表1 岩体质量分级标准
Table 1
| 类别 | RQD/% | Rw/MPa | Kv | Kf | ω/[L·(min·10m)-1] |
|---|---|---|---|---|---|
| Ⅰ | 90~100 | 200~120 | 1.00~0.75 | 1.0~0.8 | 0~5 |
| Ⅱ | 75~90 | 120~60 | 0.75~0.45 | 0.8~0.6 | 5~10 |
| Ⅲ | 50~75 | 60~30 | 0.45~0.30 | 0.6~0.4 | 10~25 |
| Ⅳ | 25~50 | 30~15 | 0.30~0.20 | 0.4~0.2 | 25~125 |
| Ⅴ | 0~25 | 15~0 | 0.20~0.00 | 0.2~0.0 | 125~300 |
2.2 学习样本建立
Two-stage TrAdaBoost.R2改进算法没有考虑多个源领域的问题,当存在多个源领域时,可将所有的源领域数据合并成为一个数据集,将多个可用的领域综合起来利用,以达到更好的迁移效果。
将上述60个样本合并为训练集,采用孤立森林模型进行评价,模型将第1、2、3、14、15、16、17组判别为异常点(表2)。异常点集中分布在I类和V类岩体中,其原因是本文所收集到的样本中,I级和V级样本数量较少,因此孤立森林模型认为其是发生概率较低、分布稀疏且远离群体的点,即异常点,并将其剔除。利用异常点剔除后的样本集训练模型,可在一定程度上提高模型精度。
表2 训练样本
Table 2
| 序号 | RQD/% | Rw/MPa | Kv | Kf | ω/[L·(min·10m)-1] | 类别 |
|---|---|---|---|---|---|---|
| 1* | 100.0 | 200.0 | 1.00 | 1.00 | 0.0 | Ⅰ |
| 2* | 97.5 | 180.0 | 0.94 | 0.95 | 1.3 | Ⅰ |
| 3* | 95.0 | 160.0 | 0.88 | 0.90 | 2.5 | Ⅰ |
| 4 | 92.5 | 140.0 | 0.81 | 0.85 | 3.8 | Ⅰ |
| 5 | 86.3 | 105.0 | 0.68 | 0.75 | 6.3 | Ⅱ |
| 6 | 82.5 | 90.0 | 0.60 | 0.70 | 7.5 | Ⅱ |
| 7 | 78.8 | 75.0 | 0.53 | 0.65 | 8.8 | Ⅱ |
| 8 | 68.8 | 52.5 | 0.41 | 0.55 | 13.8 | Ⅲ |
| 9 | 62.5 | 45.0 | 0.38 | 0.50 | 17.5 | Ⅲ |
| 10 | 56.3 | 37.5 | 0.34 | 0.45 | 21.3 | Ⅲ |
| 11 | 43.8 | 26.3 | 0.28 | 0.35 | 50.0 | Ⅳ |
| 12 | 37.5 | 22.5 | 0.25 | 0.30 | 75.0 | Ⅳ |
| 13 | 31.3 | 18.8 | 0.23 | 0.25 | 100.0 | Ⅳ |
| 14* | 18.8 | 11.3 | 0.15 | 0.15 | 168.8 | Ⅴ |
| 15* | 12.5 | 7.5 | 0.10 | 0.10 | 212.5 | Ⅴ |
| 16* | 6.3 | 3.8 | 0.05 | 0.05 | 256.3 | Ⅴ |
| 17* | 0.0 | 0.0 | 0.00 | 0.00 | 300.0 | Ⅴ |
| 18 | 82.0 | 95.0 | 0.70 | 0.35 | 20.0 | Ⅱ |
| 19 | 68.0 | 90.0 | 0.57 | 0.35 | 20.0 | Ⅱ |
| 20 | 40.0 | 25.0 | 0.22 | 0.35 | 20.0 | Ⅳ |
| 21 | 87.0 | 95.0 | 0.70 | 0.50 | 10.0 | Ⅱ |
| 22 | 76.0 | 90.0 | 0.57 | 0.50 | 10.0 | Ⅱ |
| 23 | 76.0 | 95.0 | 0.70 | 0.50 | 10.0 | Ⅱ |
| 24 | 72.0 | 90.0 | 0.57 | 0.50 | 10.0 | Ⅱ |
| 25 | 51.0 | 40.0 | 0.38 | 0.50 | 10.0 | Ⅲ |
| 26 | 52.0 | 25.0 | 0.22 | 0.50 | 10.0 | Ⅲ |
| 27 | 68.0 | 90.0 | 0.38 | 0.30 | 20.0 | Ⅲ |
| 28 | 28.0 | 40.0 | 0.32 | 0.30 | 20.0 | Ⅳ |
| 29 | 51.0 | 25.0 | 0.15 | 0.30 | 20.0 | Ⅳ |
| 30 | 75.0 | 95.0 | 0.70 | 0.50 | 0.0 | Ⅱ |
| 31 | 77.5 | 90.0 | 0.57 | 0.45 | 10.0 | Ⅱ |
| 32 | 75.5 | 90.0 | 0.45 | 0.52 | 8.0 | Ⅱ |
| 33 | 85.5 | 94.0 | 0.65 | 0.55 | 0.0 | Ⅱ |
| 34 | 85.0 | 93.0 | 0.60 | 0.50 | 0.0 | Ⅱ |
| 35 | 78.5 | 92.0 | 0.55 | 0.50 | 6.0 | Ⅱ |
| 36 | 80.0 | 95.0 | 0.50 | 0.45 | 0.0 | Ⅱ |
| 37 | 85.0 | 92.0 | 0.70 | 0.50 | 10.0 | Ⅱ |
| 38 | 78.0 | 80.0 | 0.75 | 0.50 | 0.0 | Ⅱ |
| 39 | 76.5 | 90.0 | 0.55 | 0.50 | 10.0 | Ⅱ |
| 40 | 85.0 | 95.0 | 0.65 | 0.50 | 0.0 | Ⅱ |
| 41 | 75.0 | 90.0 | 0.55 | 0.50 | 7.0 | Ⅱ |
| 42 | 75.0 | 90.0 | 0.55 | 0.50 | 10.0 | Ⅱ |
| 43 | 87.0 | 95.0 | 0.50 | 0.45 | 0.0 | Ⅱ |
| 44 | 82.0 | 96.0 | 0.75 | 0.35 | 0.0 | Ⅱ |
| 45 | 50.0 | 70.0 | 0.50 | 0.35 | 5.0 | Ⅲ |
| 46 | 50.6 | 26.0 | 0.26 | 0.35 | 20.0 | Ⅲ |
| 47 | 50.0 | 40.2 | 0.50 | 0.50 | 10.0 | Ⅲ |
| 48 | 52.0 | 25.0 | 0.20 | 0.50 | 5.0 | Ⅲ |
| 49 | 71.0 | 90.0 | 0.35 | 0.30 | 5.0 | Ⅲ |
| 50 | 50.9 | 34.0 | 0.32 | 0.35 | 21.0 | Ⅲ |
| 51 | 50.0 | 90.0 | 0.50 | 0.25 | 5.0 | Ⅲ |
| 52 | 30.2 | 70.0 | 0.40 | 0.20 | 10.0 | Ⅲ |
| 53 | 50.0 | 45.0 | 0.12 | 0.30 | 5.0 | Ⅲ |
| 54 | 51.0 | 35.0 | 0.32 | 0.35 | 15.0 | Ⅲ |
| 55 | 50.9 | 34.0 | 0.32 | 0.35 | 20.0 | Ⅲ |
| 56 | 50.0 | 45.0 | 0.15 | 0.35 | 5.0 | Ⅲ |
| 57 | 26.0 | 36.0 | 0.22 | 0.35 | 5.0 | Ⅳ |
| 58 | 31.5 | 20.0 | 0.23 | 0.25 | 46.0 | Ⅳ |
| 59 | 35.0 | 70.5 | 0.35 | 0.30 | 10.0 | Ⅳ |
| 60 | 31.5 | 20.0 | 0.23 | 0.25 | 50.0 | Ⅳ |
2.3 模型验证
(1)测试样本建立
利用广州抽水蓄能电站第1期地下工程的12个样本进行模型验证,测试样本如表3所示。
表3 测试样本
Table 3
| 序号 | RQD/% | Rw/MPa | Kv | Kf | ω/[L·(min·10m)-1] | 实测等级 |
|---|---|---|---|---|---|---|
| 1 | 71.8 | 90.1 | 0.57 | 0.45 | 0 | Ⅱ |
| 2 | 76.0 | 95.0 | 0.70 | 0.55 | 12.0 | Ⅱ |
| 3 | 87.0 | 95.0 | 0.70 | 0.50 | 9.8 | Ⅱ |
| 4 | 82.0 | 95.0 | 0.70 | 0.35 | 0 | Ⅱ |
| 5 | 76.0 | 90.0 | 0.57 | 0.50 | 11.0 | Ⅱ |
| 6 | 68.0 | 90.0 | 0.57 | 0.35 | 18.5 | Ⅱ |
| 7 | 51.0 | 40.2 | 0.38 | 0.55 | 10.5 | Ⅲ |
| 8 | 50.0 | 35.0 | 0.32 | 0.35 | 20.0 | Ⅲ |
| 9 | 68.0 | 90.0 | 0.38 | 0.38 | 21.0 | Ⅲ |
| 10 | 51.0 | 45.0 | 0.15 | 0.30 | 5.0 | Ⅲ |
| 11 | 52.0 | 25.0 | 0.22 | 0.52 | 12.0 | Ⅲ |
| 12 | 28 | 40 | 0.32 | 0.30 | 18.5 | Ⅳ |
(2)预测结果分析
由于模型训练结果具有一定的随机性,相同的参数训练出来的模型,可能会对测试样本有不同的预测结果,因此进行10次模型训练和等级预测。测试结果如表4所示。
表4 测试结果
Table 4
| 序号 | 期望输出 | 实际输出 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 均方误差 | 0.083 | 0.167 | 0.167 | 0 | 0 | 0.083 | 0 | 0 | 0.083 | 0.083 | |
| 1 | Ⅱ | 2 | 3* | 3* | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 2 | Ⅱ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 3 | Ⅱ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 4 | Ⅱ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 5 | Ⅱ | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 6 | Ⅱ | 3* | 3* | 3* | 2 | 2 | 3* | 2 | 2 | 3* | 3* |
| 7 | Ⅲ | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 8 | Ⅲ | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 9 | Ⅲ | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 10 | Ⅲ | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 11 | Ⅲ | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 12 | Ⅳ | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
第1组样本的期望输出等级为Ⅱ级,实际输出等级2次误判为3级;第6组样本的期望输出等级为Ⅱ级,实际输出等级6次误判为3级。
根据测试结果,模型判别结果的平均均方误差为0.067,整体准确率较高。对于Ⅲ级和Ⅳ级岩体,模型的判别准确率为100%;对于Ⅱ级岩体,有2组样本存在被误判为Ⅲ级的情况,判别结果在合理的误差范围内,具有一定的工程指导意义。
3 结论
(1)将迁移学习的思想引入岩体质量分级中,解决了训练样本不足的问题,实现了在目标领域学习样本较少的情况下模型的高精度预测。
(2)提出利用回归思想解决岩体质量等级的多分类问题,将两阶段回归迁移学习算法(Two-stage TrAdaBoost.R2)与孤立森林异常检测算法相结合,解决了TrAdaBoost算法中源领域权重下降过快的问题,消除了异常数据对模型的影响。
(3)基于改进的Two-stage TrAdaBoost.R2算法建立了岩体质量等级预测模型,利用广州抽水蓄能电站第1期地下工程的12个样本对模型进行测试,通过均方误差对模型的预测精度进行评价,测试样本的平均均方误差为0.067,预测精度较高,证明了该模型在岩体质量等级预测的应用中具有良好的性能。
http://www.goldsci.ac.cn/article/2021/1005-2518/1005-2518-2021-29-6-826.shtml

 甘公网安备 62010202000672号
甘公网安备 62010202000672号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}