运载计量是矿山的一项日常生产管理工作。运载计量一般采用人工方法进行统计,但是人工统计不具有客观性,可能影响卡车司机的工作量考核;此外还有使用激光扫描技术或地磅来精确测量矿石量,这些方法的测量精度和效率较高,但测量设备购置和系统维护成本高。相比之下,使用人工智能技术可以低成本、便捷和自动化地实现测量运载计量,其边际成本几乎为零,只需在新的测量点添置摄像头,卡车不用像地磅称重那样停下来,实现过程不需要人工参与。
高如新等[1 ] 基于双目立体视觉技术,对传送带上的煤堆体积进行了测量;毛琳琳[2 ] 基于双目立体视觉技术,对矿山、港口和粮仓等大堆物料进行了测量。双目立体视觉技术的原理是通过获取同一场景下2个角度的照片,对场景中特征点在图片中的位置进行匹配,然后计算出各个特征点的三维坐标,最后计算出煤堆的体积。影响双目立体视觉技术测量准确度的因素有:摄像机标定的精度,立体匹配的精度,煤堆体积计算离散化方法引入的误差等。但是该方法对拍摄图片的质量要求较高,体现在2个方面:一是煤堆周围不能有遮挡物,否则一定会影响煤堆的三维重建;二是煤堆所在的背景对测量结果的影响很大,也就是说如果背景中存在其他物体,需要对煤堆做分割预处理,而分割的效果又会影响测量的值。
以上问题说明本文所研究的问题不适合用双目立体视觉技术来解决,因其应用场景与本文所研究的问题差别较大,具体表现为卡车车斗壁挡住了矿石堆的下半部分,并且图片的背景较为复杂。近年来,深度学习技术得到了很大发展,被越来越多地应用于许多行业,用以解决图像和语音识别的问题。本文提出了一个基于深度学习的卡车装载矿石量估计方法,选择合适的网络构建深层卷积神经网络拟合实验样本。
1 数据准备
1.1 物理引擎
本文采用基于深度卷积神经网络的方法估计卡车装载矿石量。在深度学习领域,为了使实验结果具有更好的拟合效果,通常需要大量实验样本,在本实验中样本即为固定角度的卡车装载矿石照片。在实际矿山中,获取大量样本照片比较困难,故采用虚拟物理引擎的方法来模拟现实世界。通过使矿石单元从不同方位降落至卡车车斗内,从而形成具有不同形状的数据样本。
物理引擎是用于创建虚拟场景的程序,这个虚拟场景中物体的运动满足物理定律[3 ] 。此虚拟环境中的物体会受到重力以及物体之间相互碰撞的作用力的影响,物理引擎会计算处于这个虚拟环境中的物体所受的力以及运动轨迹。Chrono是一个跨平台的基于物理的建模与仿真基础设施,支持C++、Python和MATLAB接口。Chrono的核心是Chrono:Engine这个中间件,其C++接口可用于开发仿真软件。实验中,各个矿石单元的物理属性计算由Chrono:Engine模块完成,比如速度、位移和坐标等。Irrlicht引擎[4 ] 是一个用C++书写的高性能实时的3D引擎,跨平台且具有良好的移植性。矿石单元下落可视化部分由Chrono:irrlicht模块完成,所以代码部分重点需要调用Chrono:irrlicht模块。Irr命名空间下定义了所有的Irr引擎文件,引擎文件包括五大模块,每个模块都有自己的命名空间,分别是Irr:Core模块,Irr:Io模块,Irr:Gui模块,Irr:Scene模块和Irr:Video模块。
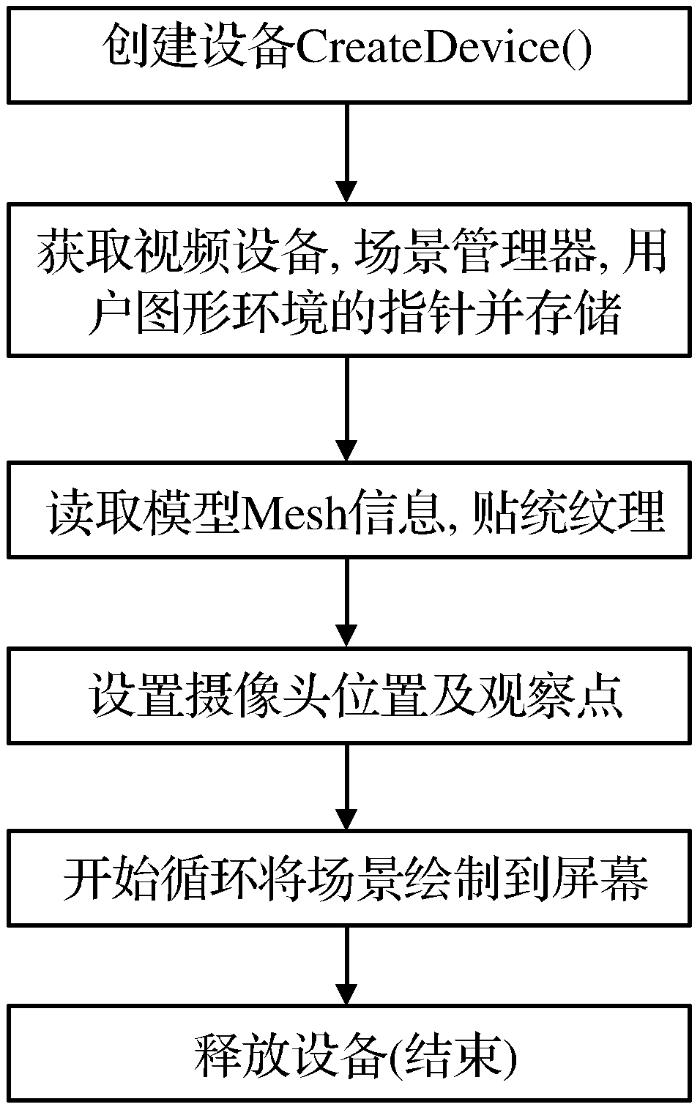
在Irr的设计中,处理的基本单元是一个个场景节点,sceneManager管理这个场景节点。Irr引擎使用流程如图1 所示。
图1
图1
Irr引擎使用流程
Fig.1
Using process of Irr engine
首先通过调用CreatDevice函数,获取一个IrrlichtDevice类的对象,这样就创建了一个设备,这个对象是使用这个引擎的根对象;然后从设备中获取视频设备(IVideoDriver类的对象),场景管理器(ISceneManager类的对象)和用户图形环境(IGUIEnvironment)的指针并存储起来;接下来便可以调用ISceneManager类的getMesh方法导入模型文件,并创建场景节点显示。Irrlicht引擎支持.obj等格式的模型文件。接着需要设置摄像头观察的目标点和摄像头的空间坐标。最后调用IvideoDriver类的beginScene方法将屏幕以指定的颜色深度和缓冲清空,使用图形用户接口(GUI)和场景管理器在内存中绘制场景,调用IvideoDriver类的endScene方法将内存中的数据绘制到屏幕上。结束时调用IrrlichtDevice类的drop方法释放掉创建的设备。
1.2 生成样本
实验中设置正方体为矿石单元,其尺寸在一个范围内随机生成,以矿石单元的总数量作为卡车装载的矿石量。将3DMax制作的卡车模型导出为obj格式文件,再将obj格式的文件作为新的场景节点导入irrlicht引擎。卡车模型不是Chrono物理系统中创建的物体单元(ChBodyEasy),无法与矿石单元交互,所以矿石并不会停留在卡车车斗中。因此需要创建底部封闭的容器加入到Chrono物理系统(ChSystem)中,并且容器的尺寸和位置与卡车车斗相匹配。将矿石块体单元在卡车车斗内的最终堆叠状态保存作为样本。各物体单元的参数如表2 所示。
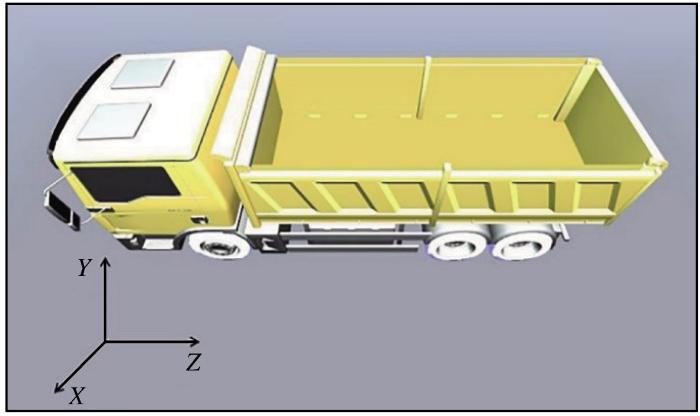
其中,摄像机的观察点为(0,0,-5)。坐标系如图2 所示。
图2
图2
样本坐标系
Fig.2
Sample coordinate system
实验共生成4批数据,这4批数据在Z 方向的范围不同,矿石单元的下落初始位置在设置范围内随机生成,同一批数据样本中矿石单元数量不重复。各批次数据参数具体设置见表3 。
从表中可以看出,第一批数据的矿石单元下落位置均匀分布在矿车车斗上方;第二批数据的矿石单元下落位置集中在靠车头一侧;第三批数据的矿石单元下落位置集中在车斗中部;第四批数据的矿石单元下落位置集中在靠车尾一侧。4批数据共计2 800个样本。
实验训练集与测试集比例为3∶1。为使测试样本分布均匀,测试样本组成如表4 所示。
2 基于卷积神经网络的矿石量估计
2.1 构建DCNN网络
自1998年Lecun提出卷积网络[5 ] 实现手写体数字的识别后,卷积神经网络被广泛应用于图像识别和自然语言处理等领域。2006年,Hinton等[6 ] 提出深度学习的概念,即深层神经网络。随着数据增多与计算能力的提升,深度卷积神经网络极大地提高了各领域的识别效果,例如手写体识别[7 ] 。本文充分利用深度卷积神经网络(DCNN)的特点,自动提取卡车装载的图像特征,对其装载量进行回归分析。
由于卡车装载矿石量估计是一个回归问题,因此采用深层神经网络拟合样本需要将最后一层的神经元数量设置为1,以最后一层神经元的值作为预测值[8 ,9 ] 。由于需要拟合的样本由计算机生成,这些样本背景单一、摄像机角度固定,故考虑使用参数量较少的网络模型开始实验[10 ] 。
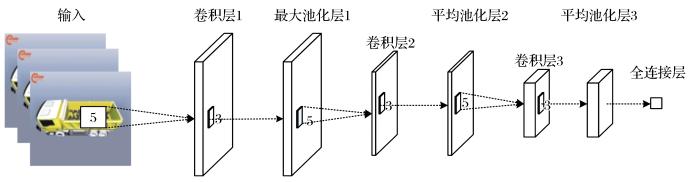
在参考了一些经典的网络结构之后,考虑以Caffe中用于测试cifar-10数据集的网络结构为基础,进行参数调整。Cifar-10数据集由60 000张32*32的RGB彩色图片构成,共10个分类,其中50 000张用于训练,10 000张用于测试,可用于普适物体的识别。按照3∶1的比例将所生成的样本划分为训练集和测试集,然后将样本的标签值进行归一化处理(将装载量除以最大可能的装载量形成0~1之间的数值)。各层网络的参数设置如表5 所示。深度卷积神经网络结构如图3 所示。
图3
图3
卷积神经网络结构图
Fig. 3
Structure diagram of convolutional neural networks
2.2 向前计算
x j l = R e l u ∑ i ∈ M j x i l - 1 * k i j l + b j l (1)
卷积层用几个可训练的卷积核与输入的特征图进行卷积,再通过激活函数得到输出的特征图,输出的每个特征图可能是与多个输入特征图卷积而来。R e l u M j x j l l 层第j 个特征图中的值,x i l - 1 l- 1层M j k i j l b [12 ] 。网络中池化层的定义为
x j l = d o w n x j l - 1 (2)
一个池化层产生输入特征图的一个下采样层。如果有n 个输入特征图,就会产生n 个输出特征图。down (.)表示一个子采样函数,一个典型的函数是对输入特征图中的n *n 大小的像素块求平均,这样输出特征图在每个维度上都减小n 倍。
Relu 函数定义如式(3)所示。在采用随机梯度下降优化参数时,用Relu 激活函数的训练速度比tanh 或sigmoid 这些非线性函数要快许多,深度神经网络用Relu 的训练速度比tanh 快几倍[13 ] 。
R e l u x = m a x 0 , x (3)
网络在池化层后接一个局部响应归一化层,一般用Relu 作为激活函数时不需要用局部归一化,因为Relu 可以避免神经元出现饱和(saturating)的现象,只要有一些大于零的输入,学习过程就可以发生在这些神经元上。但是Relu 后使用局部归一化也能够提高网络的泛化能力。局部响应归一化的过程是当前卷积核的激活值除以附近n 个卷积核激活值的平方和的若干倍的若干次方,定义为
b x , y i = a x , y i / k + α ∑ j = m a x 0 , i - n / 2 m i n N - 1 , i + n / 2 a x , y j 2 β (4)
式中:求和操作是针对附近n 个特征图中对应位置的激活值,N 是该层中特征图的数量,在训练开始前卷积核的顺序是随机的[14 ] 。k , n , α , β k = 3 , n = 3 , α = 0.00005 , β = 0.75
2.3 梯度计算
E N = 1 2 N ∑ i = 1 N x i - y i 2 2 (5)
因为整个数据集的误差是单个样本误差之和,所以针对单个样本考虑误差反向传播的过程,则第n 个样本的误差定义为
E n = 1 2 x n - y n 2 2 (6)
在传统的全连接层中,可以用如下形式的反向传播公式计算E 对每个权重的偏导。用l 表示当前层,用L 表示输出层,定义当前层的输出[15 ] :x l = f u l
u l = W l x l - 1 + b l (7)
在网络中反向传播的误差可以看作是每个神经元对bias 扰动的灵敏度,可表示为:
∂ E ∂ b = ∂ E ∂ u ∂ u ∂ b = δ (8)
x l ∂ u ∂ b = 1 E 对b 的偏导同误差对一个节点的全部输入的偏导相等。这个导数就是从高层到低层反向传播得到的,对第l层的导数如下:
δ l = W l + 1 T δ l + 1 ∘ f ' u l (9)
∘ L 表示输出层),故
δ L = f ' u L ∘ x n - y n (10)
然后,用δ δ η ∂ E ∂ W l = x l - 1 δ l T
∆ W l = - η ∂ E ∂ W l (11)
网络结构中每个卷积层后接一个池化层,设卷积层为第l 层,池化层为第l+ 1层,反向传播算法为了计算第l 层中神经元的偏导值,应当首先对l+ 1层中与当前神经元相连的神经元的偏导值求和,然后乘以这些连接在l+ 1层中定义的权值。接着乘以激活函数对当前神经元输入的导数值。由于卷积层后接池化层,l+ 1层中神经元的偏导δ l 层的一整块区域的神经元,因此l 层中每个神经元只与l+ 1层中的一个神经元相连。为了高效计算l 层的敏感度,可以对l+ 1层神经元的敏感度通过上采样得到与l 层同等大小的敏感度map,然后将l 层的敏感度map逐元素乘以l 层激活函数对神经元的导数[16 ] 。因为在下采样中定义的权重值是个常量,所以再对上述步骤得到的值缩放β l 层的敏感度δ l
δ j l = β j l + 1 f ' u j l ∘ u p δ j l + 1 (12)
式中:u p · N*N 的像素块,则上采样时单个像素与N*N 的像素块关联。下面来讨论,可高效执行这个函数的Kronecker乘法:
u p x = x ⨂ 1 n × n (13)
笔者得到了l 层的敏感度map,可以通过对δ l i [17 ] ,如下式所示:
∂ E ∂ b j = ∑ u , v δ j l u v (14)
最后,通过反向传播求卷积核的梯度。正如求偏置的梯度一样,卷积核是被多个连接所共享的,因此需要对所有连接传递的梯度求和得到卷积核权重的梯度:
∂ E ∂ k i j l = ∑ u , v δ j l u v p i l - 1 u v (15)
p i l - 1 u v x i l - 1 k i j l x j l u,v )的元素的那部分神经元。直觉上可能会认为寻找该部分神经元和相应的敏感度map很困难,但是式(16)能够用一行MATLAB代码实现:
∂ E ∂ k i j l = r o t 180 c o n v 2 x i l - 1 , r o t 180 δ j l , ‘ v a l i d ’ (16)
这里通过旋转敏感度map进行相互作用计算,并且要再次旋转返回到原来的位置,这样下次进行前向计算时卷积核的位置才是正确的。
3 实验及分析
3.1 实验参数与实验平台
利用物理引擎生成的样本共2 800张,按照3∶1的比例将所生成的样本划分为训练集和测试集,测试样本的组成如表3 所示,剩余样本用于训练。对样本的标签值进行归一化处理(将装载量除以最大可能的装载量形成0~1之间的数值),例如有500个矿石单元的样本标签值为0.5。
DCNN网络的训练参数设置如下:最大迭代次数MaxIter设置为4 000,学习率α 设置为0.001,动量因子μ 设置为0.9,正则项系数WeightDecay设置为0.004,优化算法采用Nesterov[18 ] 。
实验拟采用GTX TITAN X GPU GeForce硬件平台以及深度学习框架Caffe软件平台。作为一种高效的深度学习框架,该方法使用Protobuf配置文件定义网络结构,能够有效支持卷积神经网络,实现在GPU上的高速运算。另外,Caffe是纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口,可以在CPU和GPU直接无缝切换。
3.2 可视化分析
深度学习的发展得益于大量带标签数据的出现和计算机运算能力的提升。但深层次的神经网络模型为何能取得如此好的识别效果,至今仍然没有完善的科学解释。许多学者把神经网络看作一个黑盒模型,基于经验和试错法来调整参数,改进模型[19 ] 。虽然无法完全打开这个黑盒,但可视化的方法可以让我们对网络实现的过程多一些理解。其中,Krizhevshy等[20 ] 建立的AlexNet网络结构模型对第一个卷积层的卷积核进行了可视化操作,Zeiler等[21 ] 对可视化分析做了更深入的研究。本网络第一层的卷积核可视化如图4 所示。
图4
图4
卷积1层卷积核图
Fig.4
Convolution kernel of conv1 layer
从图中可以看出,第一层卷积核没有明显的提取边缘特征,但是有明显的颜色特征。比如黄色的卷积核是提取了卡车的颜色信息,与背景颜色相近的卷积核是提取了背景信息,颜色较暗的卷积核则是提取了矿石信息。
图5 所示为提取卡车颜色信息的卷积核。其中,上部分是卷积核图,下部分是对应的特征图。左半部分是提取卡车信息的图,可以明显看出卡车车身的轮廓,因为卡车车身的颜色与卷积核的颜色相匹配;右半部分是提取背景信息的图,可以看出卷积核的颜色与图片的背景色很接近,于是所对应的特征图里显示的是背景信息。
图5
图5
提取卡车信息与背景信息图
Fig.5
Extracting truck information and background information
以上关于矿石信息、车身信息和背景信息的观察表明每个卷积核所提取的特征均不相同,而提取矿石信息的卷积核有效保证了模型对矿石量估计的可靠性,同时也说明模型较好地学到了相关特征。
3.3 实验结果
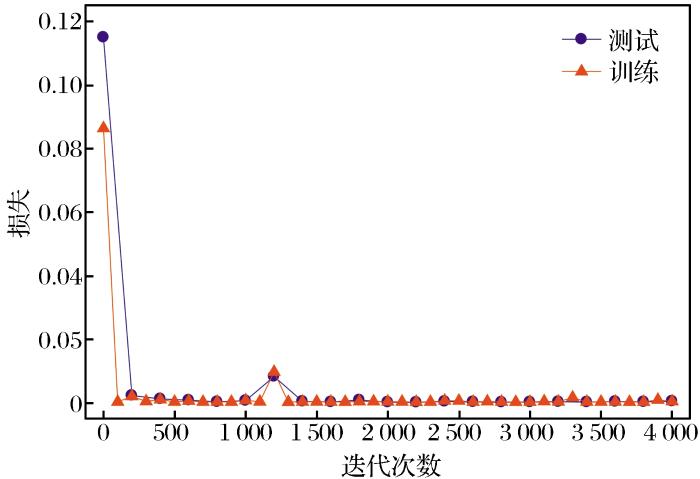
该DCNN网络训练与测试的Loss在迭代过程中的变化情况如图6 所示。
图6
图6
训练与测试的损失变化图
Fig.6
The loss change of training and testing
实验基于Caffe平台,显卡是GTX TITAN X GPU GeForce,网络训练时间为20 min,测试单张图片的时间约为0.2 s。实验数据显示,测试和训练误差在10-4 量级,因此平均误差大概在10-2 量级,这样的误差对于实际应用是完全可以接受的。
一般来讲,计算机对矿石量的识别误差在10%以内是可以接受的。当绝大部分的预测误差在此范围内时,说明模型达到了理想的优化结果。故以该网络模型在测试集上的误差分布来衡量模型的性能,该网络模型在测试集上样本的误差分布如图7 所示。
图7
图7
测试集样本的误差分布图
Fig.7
Error distribution of test set samples
横轴表示预测值与真实值之差的绝对值,纵轴表示误差在该区间的样本数量。从图中可以看出,大部分样本的误差在4%以内,几乎所有的样本误差都在10%以内,表明该网络模型已经足够好地拟合了实验的数据集。
4 结语
本文的实验结果说明卷积神经网络可以解决卡车装载矿石量估计这样的回归问题,同时也证明了用深度学习的方法对实际场景下卡车装载矿石量进行估计的可行性。本文所构建的卷积网络在实验所用的数据集上预测准确度很高(大部分测试样本误差在4%以内),在实际应用中完全可以接受。通过可视化特征图与卷积核可以看到部分卷积核关注矿石区域的信息,这对于理解卷积网络解决该问题的过程有所帮助。
本文的实验效果虽然理想,但数据集中图片背景比较单一,而光照、拍摄角度等因素对自然场景下拍摄的图片有较大影响,背景发生变化可能影响图像识别的效果。如果矿石单元在卡车车斗内存在凹形,则通过单角度识别图像来估计矿石量也可能有较大误差。后续的研究可以考虑在复杂背景下进行矿石单元的识别,并且多角度拍摄自然场景下的矿体,以多角度的图片作为输入信息,考虑多角度图片的融合问题,并且考虑将卡车先检测出来之后再进行网络参数的训练。
参考文献
View Option
[1]
高如新 ,王俊孟 .基于双目立体视觉的煤体积测量
[J].计算机系统应用 ,2014 ,23 (5 ):126 -133 .
[本文引用: 1]
Gao Ruxin , Wang Junmeng .Volume measurement of coal based on binocular stereo vision
[J].Computer Systems and Applications ,2014 ,23 (5 ):126 -133 .
[本文引用: 1]
[2]
毛琳琳 .基于双目立体视觉的大堆物料体积测量方法研究
[D].杭州 :中国计量学院 ,2015 .
[本文引用: 1]
Mao Linlin .Research on Measurement Method for Piles of Material Volume Based on Binocular Stereo Vision
[D].Hangzhou :China Jiliang University ,2015 .
[本文引用: 1]
[3]
段化鹏 .虚拟现实中物理引擎关键技术的研究与应用
[D].青岛 :山东科技大学 ,2010 .
[本文引用: 1]
Duan Huapeng .Research and Application of Physics Engine Key Techniques in Virtual Reality
[D].Qingdao :Shandong University of Science and Technology ,2010 .
[本文引用: 1]
[4]
康宇 .基于Irrlicht引擎的3D游戏的设计与实现
[D].长春 :吉林大学 ,2012 .
[本文引用: 1]
Kang Yu .Design and Implementation of 3D Game Based on the Irrlicht Engine
[D].Changchun :Jilin University , 2012 .
[本文引用: 1]
[5]
Lécun Y , Bottou L , Bengio Y ,et al .Gradient-based learning applied to document recognition
[J].Proceedings of the IEEE ,1998 ,86 (11 ):2278 -2324 .
[本文引用: 1]
[6]
Hinton G E , Osindero S , Teh Y W .A fast learning algorithm for deep belief nets
[J].Neural Computer ,2006 ,18 (7 ):1527 -1554 .
[本文引用: 1]
[7]
Ciresan D C , Meier U , Gambardella L M , et al .Deep,big,simple neural nets for handwritten digit recognition
[J].Neural Computation ,2010 (12 ):3207 -3220 .
[本文引用: 1]
[8]
Pitts W . A Logical Calculus of the Ideas Immanent in Nervous Activity
[M]//Neurocomputing :Foundations of Research.Cambridge :The Massachusetts Institute of Technology Press ,1988 :115 -133 .
[本文引用: 1]
[9]
Hagan M T , Beale M , Beale M .Neural Network Design
[M].Beijing :China Machine Press ,2002 .
[本文引用: 1]
[10]
Wang T , Wu D J , Coates A ,et al .End-to-end text recognition with convolutional neural networks
[C]//International Conference on Pattern Recognition IEEE ,2013 :3304 -3308 .
[本文引用: 1]
[11]
Li H , Lin Z , Shen X ,et al .A convolutional neural network cascade for face detection
[C]//Computer Vision and Pattern Recognition IEEE ,2015 :5325 -5334 .
[本文引用: 1]
[12]
Lecun Y , Boser B , Denker J S ,et al .Backpropagation applied to handwritten zip code recognition
[J].Neural Computation ,2014 ,1 (4 ):541 -551 .
[本文引用: 1]
[13]
Gulcehre C , Moczulski M , Denil M ,et al .Noisy activation functions
[C]//International Conference on Machine Learning.New York:Journal of Machine Learning Research ,2016 :3059 -3068 .
[本文引用: 1]
[14]
Ioffe S , Szegedy C .Batch normalization:Accelerating deep network training by reducing internal covariate shift
[C]//International Conference on Machine Learning. Lille:Journal of Machine Learning Research ,2015 :448 -456 .
[本文引用: 1]
[15]
Bouvrie J .Notes on convolutional neural networks
[R].Massachusetts :Center for Biological and Computational Learning ,2006 :38 -44 .
[本文引用: 1]
[16]
Glorot X , Bengio Y .Understanding the difficulty of training deep feedforward neural networks
[J].Journal of Machine Learning Research ,2010 ,9 :249 -256 .
[本文引用: 1]
[17]
Nair V , Hinton G E .Rectified linear units improve restricted boltzmann machines
[C]//International Conference on Machine Learning.Haifa:Journal of Machine Learning Research ,2010 :807 -814 .
[本文引用: 1]
[18]
Su W , Boyd S , Candes E J .A differential equation for modeling nesterov’s accelerated gradient method:Theory and insights
[J].Advances in Neural Information Processing Systems ,2015 ,3 (1 ):2510 -2518 .
[本文引用: 1]
[19]
Wallach I , Dzamba M , Heifets A .AtomNet:A deep convolutional neural network for bioactivity prediction in structure-based drug discovery
[J].Mathematische Zeitschrift ,2015 ,47 (1 ):34 -46 .
[本文引用: 1]
[20]
Krizhevsky A , Sutskever I , Hinton G E .ImageNet classification with deep convolutional neural networks
[J].Communications of the Association for Computing Machinery ,2017 ,60 (6 ):84 -90 .
[本文引用: 1]
[21]
Zeiler M D , Fergus R .Visualizing and understanding convolutional networks
[C]//European Conference on Computer Vision. Switzerland:Springer ,2014 :818 -833 .
[本文引用: 1]
基于双目立体视觉的煤体积测量
1
2014
... 高如新等[1 ] 基于双目立体视觉技术,对传送带上的煤堆体积进行了测量;毛琳琳[2 ] 基于双目立体视觉技术,对矿山、港口和粮仓等大堆物料进行了测量.双目立体视觉技术的原理是通过获取同一场景下2个角度的照片,对场景中特征点在图片中的位置进行匹配,然后计算出各个特征点的三维坐标,最后计算出煤堆的体积.影响双目立体视觉技术测量准确度的因素有:摄像机标定的精度,立体匹配的精度,煤堆体积计算离散化方法引入的误差等.但是该方法对拍摄图片的质量要求较高,体现在2个方面:一是煤堆周围不能有遮挡物,否则一定会影响煤堆的三维重建;二是煤堆所在的背景对测量结果的影响很大,也就是说如果背景中存在其他物体,需要对煤堆做分割预处理,而分割的效果又会影响测量的值. ...
基于双目立体视觉的煤体积测量
1
2014
... 高如新等[1 ] 基于双目立体视觉技术,对传送带上的煤堆体积进行了测量;毛琳琳[2 ] 基于双目立体视觉技术,对矿山、港口和粮仓等大堆物料进行了测量.双目立体视觉技术的原理是通过获取同一场景下2个角度的照片,对场景中特征点在图片中的位置进行匹配,然后计算出各个特征点的三维坐标,最后计算出煤堆的体积.影响双目立体视觉技术测量准确度的因素有:摄像机标定的精度,立体匹配的精度,煤堆体积计算离散化方法引入的误差等.但是该方法对拍摄图片的质量要求较高,体现在2个方面:一是煤堆周围不能有遮挡物,否则一定会影响煤堆的三维重建;二是煤堆所在的背景对测量结果的影响很大,也就是说如果背景中存在其他物体,需要对煤堆做分割预处理,而分割的效果又会影响测量的值. ...
基于双目立体视觉的大堆物料体积测量方法研究
1
2015
... 高如新等[1 ] 基于双目立体视觉技术,对传送带上的煤堆体积进行了测量;毛琳琳[2 ] 基于双目立体视觉技术,对矿山、港口和粮仓等大堆物料进行了测量.双目立体视觉技术的原理是通过获取同一场景下2个角度的照片,对场景中特征点在图片中的位置进行匹配,然后计算出各个特征点的三维坐标,最后计算出煤堆的体积.影响双目立体视觉技术测量准确度的因素有:摄像机标定的精度,立体匹配的精度,煤堆体积计算离散化方法引入的误差等.但是该方法对拍摄图片的质量要求较高,体现在2个方面:一是煤堆周围不能有遮挡物,否则一定会影响煤堆的三维重建;二是煤堆所在的背景对测量结果的影响很大,也就是说如果背景中存在其他物体,需要对煤堆做分割预处理,而分割的效果又会影响测量的值. ...
基于双目立体视觉的大堆物料体积测量方法研究
1
2015
... 高如新等[1 ] 基于双目立体视觉技术,对传送带上的煤堆体积进行了测量;毛琳琳[2 ] 基于双目立体视觉技术,对矿山、港口和粮仓等大堆物料进行了测量.双目立体视觉技术的原理是通过获取同一场景下2个角度的照片,对场景中特征点在图片中的位置进行匹配,然后计算出各个特征点的三维坐标,最后计算出煤堆的体积.影响双目立体视觉技术测量准确度的因素有:摄像机标定的精度,立体匹配的精度,煤堆体积计算离散化方法引入的误差等.但是该方法对拍摄图片的质量要求较高,体现在2个方面:一是煤堆周围不能有遮挡物,否则一定会影响煤堆的三维重建;二是煤堆所在的背景对测量结果的影响很大,也就是说如果背景中存在其他物体,需要对煤堆做分割预处理,而分割的效果又会影响测量的值. ...
虚拟现实中物理引擎关键技术的研究与应用
1
2010
... 物理引擎是用于创建虚拟场景的程序,这个虚拟场景中物体的运动满足物理定律[3 ] .此虚拟环境中的物体会受到重力以及物体之间相互碰撞的作用力的影响,物理引擎会计算处于这个虚拟环境中的物体所受的力以及运动轨迹.Chrono是一个跨平台的基于物理的建模与仿真基础设施,支持C++、Python和MATLAB接口.Chrono的核心是Chrono:Engine这个中间件,其C++接口可用于开发仿真软件.实验中,各个矿石单元的物理属性计算由Chrono:Engine模块完成,比如速度、位移和坐标等.Irrlicht引擎[4 ] 是一个用C++书写的高性能实时的3D引擎,跨平台且具有良好的移植性.矿石单元下落可视化部分由Chrono:irrlicht模块完成,所以代码部分重点需要调用Chrono:irrlicht模块.Irr命名空间下定义了所有的Irr引擎文件,引擎文件包括五大模块,每个模块都有自己的命名空间,分别是Irr:Core模块,Irr:Io模块,Irr:Gui模块,Irr:Scene模块和Irr:Video模块. ...
虚拟现实中物理引擎关键技术的研究与应用
1
2010
... 物理引擎是用于创建虚拟场景的程序,这个虚拟场景中物体的运动满足物理定律[3 ] .此虚拟环境中的物体会受到重力以及物体之间相互碰撞的作用力的影响,物理引擎会计算处于这个虚拟环境中的物体所受的力以及运动轨迹.Chrono是一个跨平台的基于物理的建模与仿真基础设施,支持C++、Python和MATLAB接口.Chrono的核心是Chrono:Engine这个中间件,其C++接口可用于开发仿真软件.实验中,各个矿石单元的物理属性计算由Chrono:Engine模块完成,比如速度、位移和坐标等.Irrlicht引擎[4 ] 是一个用C++书写的高性能实时的3D引擎,跨平台且具有良好的移植性.矿石单元下落可视化部分由Chrono:irrlicht模块完成,所以代码部分重点需要调用Chrono:irrlicht模块.Irr命名空间下定义了所有的Irr引擎文件,引擎文件包括五大模块,每个模块都有自己的命名空间,分别是Irr:Core模块,Irr:Io模块,Irr:Gui模块,Irr:Scene模块和Irr:Video模块. ...
基于Irrlicht引擎的3D游戏的设计与实现
1
2012
... 物理引擎是用于创建虚拟场景的程序,这个虚拟场景中物体的运动满足物理定律[3 ] .此虚拟环境中的物体会受到重力以及物体之间相互碰撞的作用力的影响,物理引擎会计算处于这个虚拟环境中的物体所受的力以及运动轨迹.Chrono是一个跨平台的基于物理的建模与仿真基础设施,支持C++、Python和MATLAB接口.Chrono的核心是Chrono:Engine这个中间件,其C++接口可用于开发仿真软件.实验中,各个矿石单元的物理属性计算由Chrono:Engine模块完成,比如速度、位移和坐标等.Irrlicht引擎[4 ] 是一个用C++书写的高性能实时的3D引擎,跨平台且具有良好的移植性.矿石单元下落可视化部分由Chrono:irrlicht模块完成,所以代码部分重点需要调用Chrono:irrlicht模块.Irr命名空间下定义了所有的Irr引擎文件,引擎文件包括五大模块,每个模块都有自己的命名空间,分别是Irr:Core模块,Irr:Io模块,Irr:Gui模块,Irr:Scene模块和Irr:Video模块. ...
基于Irrlicht引擎的3D游戏的设计与实现
1
2012
... 物理引擎是用于创建虚拟场景的程序,这个虚拟场景中物体的运动满足物理定律[3 ] .此虚拟环境中的物体会受到重力以及物体之间相互碰撞的作用力的影响,物理引擎会计算处于这个虚拟环境中的物体所受的力以及运动轨迹.Chrono是一个跨平台的基于物理的建模与仿真基础设施,支持C++、Python和MATLAB接口.Chrono的核心是Chrono:Engine这个中间件,其C++接口可用于开发仿真软件.实验中,各个矿石单元的物理属性计算由Chrono:Engine模块完成,比如速度、位移和坐标等.Irrlicht引擎[4 ] 是一个用C++书写的高性能实时的3D引擎,跨平台且具有良好的移植性.矿石单元下落可视化部分由Chrono:irrlicht模块完成,所以代码部分重点需要调用Chrono:irrlicht模块.Irr命名空间下定义了所有的Irr引擎文件,引擎文件包括五大模块,每个模块都有自己的命名空间,分别是Irr:Core模块,Irr:Io模块,Irr:Gui模块,Irr:Scene模块和Irr:Video模块. ...
Gradient-based learning applied to document recognition
1
1998
... 自1998年Lecun提出卷积网络[5 ] 实现手写体数字的识别后,卷积神经网络被广泛应用于图像识别和自然语言处理等领域.2006年,Hinton等[6 ] 提出深度学习的概念,即深层神经网络.随着数据增多与计算能力的提升,深度卷积神经网络极大地提高了各领域的识别效果,例如手写体识别[7 ] .本文充分利用深度卷积神经网络(DCNN)的特点,自动提取卡车装载的图像特征,对其装载量进行回归分析. ...
A fast learning algorithm for deep belief nets
1
2006
... 自1998年Lecun提出卷积网络[5 ] 实现手写体数字的识别后,卷积神经网络被广泛应用于图像识别和自然语言处理等领域.2006年,Hinton等[6 ] 提出深度学习的概念,即深层神经网络.随着数据增多与计算能力的提升,深度卷积神经网络极大地提高了各领域的识别效果,例如手写体识别[7 ] .本文充分利用深度卷积神经网络(DCNN)的特点,自动提取卡车装载的图像特征,对其装载量进行回归分析. ...
Deep,big,simple neural nets for handwritten digit recognition
1
... 自1998年Lecun提出卷积网络[5 ] 实现手写体数字的识别后,卷积神经网络被广泛应用于图像识别和自然语言处理等领域.2006年,Hinton等[6 ] 提出深度学习的概念,即深层神经网络.随着数据增多与计算能力的提升,深度卷积神经网络极大地提高了各领域的识别效果,例如手写体识别[7 ] .本文充分利用深度卷积神经网络(DCNN)的特点,自动提取卡车装载的图像特征,对其装载量进行回归分析. ...
A Logical Calculus of the Ideas Immanent in Nervous Activity
1
1988
... 由于卡车装载矿石量估计是一个回归问题,因此采用深层神经网络拟合样本需要将最后一层的神经元数量设置为1,以最后一层神经元的值作为预测值[8 ,9 ] .由于需要拟合的样本由计算机生成,这些样本背景单一、摄像机角度固定,故考虑使用参数量较少的网络模型开始实验[10 ] . ...
Neural Network Design
1
2002
... 由于卡车装载矿石量估计是一个回归问题,因此采用深层神经网络拟合样本需要将最后一层的神经元数量设置为1,以最后一层神经元的值作为预测值[8 ,9 ] .由于需要拟合的样本由计算机生成,这些样本背景单一、摄像机角度固定,故考虑使用参数量较少的网络模型开始实验[10 ] . ...
End-to-end text recognition with convolutional neural networks
1
2013
... 由于卡车装载矿石量估计是一个回归问题,因此采用深层神经网络拟合样本需要将最后一层的神经元数量设置为1,以最后一层神经元的值作为预测值[8 ,9 ] .由于需要拟合的样本由计算机生成,这些样本背景单一、摄像机角度固定,故考虑使用参数量较少的网络模型开始实验[10 ] . ...
A convolutional neural network cascade for face detection
1
2015
Backpropagation applied to handwritten zip code recognition
1
2014
... 卷积层用几个可训练的卷积核与输入的特征图进行卷积,再通过激活函数得到输出的特征图,输出的每个特征图可能是与多个输入特征图卷积而来.R e l u M j x j l l 层第j 个特征图中的值,x i l - 1 l- 1层M j k i j l b [12 ] .网络中池化层的定义为 ...
Noisy activation functions
1
2016
... Relu 函数定义如式(3)所示.在采用随机梯度下降优化参数时,用Relu 激活函数的训练速度比tanh 或sigmoid 这些非线性函数要快许多,深度神经网络用Relu 的训练速度比tanh 快几倍[13 ] . ...
Batch normalization:Accelerating deep network training by reducing internal covariate shift
1
2015
... 式中:求和操作是针对附近n 个特征图中对应位置的激活值,N 是该层中特征图的数量,在训练开始前卷积核的顺序是随机的[14 ] .k , n , α , β k = 3 , n = 3 , α = 0.00005 , β = 0.75 . 这个局部响应归一化的提出是受到生物学中的侧抑制现象的启发,即一个兴奋的神经元会抑制其周边的神经元,也就是提高周边神经元的阈值. ...
Notes on convolutional neural networks
1
2006
... 在传统的全连接层中,可以用如下形式的反向传播公式计算E 对每个权重的偏导.用l 表示当前层,用L 表示输出层,定义当前层的输出[15 ] :x l = f u l
Understanding the difficulty of training deep feedforward neural networks
1
2010
... 网络结构中每个卷积层后接一个池化层,设卷积层为第l 层,池化层为第l+ 1层,反向传播算法为了计算第l 层中神经元的偏导值,应当首先对l+ 1层中与当前神经元相连的神经元的偏导值求和,然后乘以这些连接在l+ 1层中定义的权值.接着乘以激活函数对当前神经元输入的导数值.由于卷积层后接池化层,l+ 1层中神经元的偏导δ l 层的一整块区域的神经元,因此l 层中每个神经元只与l+ 1层中的一个神经元相连.为了高效计算l 层的敏感度,可以对l+ 1层神经元的敏感度通过上采样得到与l 层同等大小的敏感度map,然后将l 层的敏感度map逐元素乘以l 层激活函数对神经元的导数[16 ] .因为在下采样中定义的权重值是个常量,所以再对上述步骤得到的值缩放β l 层的敏感度δ l . 可以将卷积层中的每个敏感度map与池化层中的敏感度map配对,然后重复同样的操作.整个过程可表示为 ...
Rectified linear units improve restricted boltzmann machines
1
2010
... 笔者得到了l 层的敏感度map,可以通过对δ l i [17 ] ,如下式所示: ...
A differential equation for modeling nesterov’s accelerated gradient method:Theory and insights
1
2015
... DCNN网络的训练参数设置如下:最大迭代次数MaxIter设置为4 000,学习率α 设置为0.001,动量因子μ 设置为0.9,正则项系数WeightDecay设置为0.004,优化算法采用Nesterov[18 ] . ...
AtomNet:A deep convolutional neural network for bioactivity prediction in structure-based drug discovery
1
2015
... 深度学习的发展得益于大量带标签数据的出现和计算机运算能力的提升.但深层次的神经网络模型为何能取得如此好的识别效果,至今仍然没有完善的科学解释.许多学者把神经网络看作一个黑盒模型,基于经验和试错法来调整参数,改进模型[19 ] .虽然无法完全打开这个黑盒,但可视化的方法可以让我们对网络实现的过程多一些理解.其中,Krizhevshy等[20 ] 建立的AlexNet网络结构模型对第一个卷积层的卷积核进行了可视化操作,Zeiler等[21 ] 对可视化分析做了更深入的研究.本网络第一层的卷积核可视化如图4 所示. ...
ImageNet classification with deep convolutional neural networks
1
2017
... 深度学习的发展得益于大量带标签数据的出现和计算机运算能力的提升.但深层次的神经网络模型为何能取得如此好的识别效果,至今仍然没有完善的科学解释.许多学者把神经网络看作一个黑盒模型,基于经验和试错法来调整参数,改进模型[19 ] .虽然无法完全打开这个黑盒,但可视化的方法可以让我们对网络实现的过程多一些理解.其中,Krizhevshy等[20 ] 建立的AlexNet网络结构模型对第一个卷积层的卷积核进行了可视化操作,Zeiler等[21 ] 对可视化分析做了更深入的研究.本网络第一层的卷积核可视化如图4 所示. ...
Visualizing and understanding convolutional networks
1
2014
... 深度学习的发展得益于大量带标签数据的出现和计算机运算能力的提升.但深层次的神经网络模型为何能取得如此好的识别效果,至今仍然没有完善的科学解释.许多学者把神经网络看作一个黑盒模型,基于经验和试错法来调整参数,改进模型[19 ] .虽然无法完全打开这个黑盒,但可视化的方法可以让我们对网络实现的过程多一些理解.其中,Krizhevshy等[20 ] 建立的AlexNet网络结构模型对第一个卷积层的卷积核进行了可视化操作,Zeiler等[21 ] 对可视化分析做了更深入的研究.本网络第一层的卷积核可视化如图4 所示. ...








 甘公网安备 62010202000672号
甘公网安备 62010202000672号
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}